
Meta has provided some insight into its new data center design, featuring air and liquid cooling for standard and high-density workloads.
Late last year, DCD broke the news that Meta was canceling or pausing data center projects mid-development around the world as it suddenly shifted to support artificial intelligence workloads amid a generative AI pivot.
Meta is a huge data center operator, with a DCD investigation in 2022 finding that its Prineville campus was the largest operational data center in the world. Last quarter alone, the company's capex for data centers, servers, and offices hit $7.1 billion, with the company warning investors that an AI buildout would prove expensive.
Next-gen data centers
The company needed to rethink how it makes its facilities after betting on CPUs and its own in-house chips to handle both traditional workloads and AI ones. But as AI usage has boomed, and it has become a critical competition point for big tech, CPUs have been unable to keep up.
Meta's in-house chip, meanwhile, failed to meet internal targets and a planned rollout last year was scrapped.
Now, the company hopes to embrace GPUs and has made a new attempt at an in-house chip. It has also unveiled an in-house chip for video transcoding, similar to YouTube's Argos semiconductor.
"We're experiencing growth in AI tech, [so] we need to make sure that our data center can adapt to something that's still evolving," Meta's global director of data center strategic engineering Alan Duong said at a press event detailing the company's 'Next-Generation Data Center Design.'
He added: "And we need to scale it by 4×, roughly."
Duong noted that AI "makes innovating in data center design really complex," as the company has to balance designing for workloads of today with the unknown needs of the future. "For example, over the next four years, we may see a one and a half to two times growth in power consumption per accelerator, and roughly one and a half time for high bandwidth memory."

Issue 48 - Generative AI & The Future of Data Centers
Our largest feature ever looks at the next wave of computing
Meta expects to break ground on the first of its next-gen data centers "today or this year," Duong said. "And so if we're just starting on construction for that data center, by the time we're done, we might be obsolete [unless we futureproof]."
The data center may need to support drastically different white space deployments: "Depending on what our services and products will need, we can see smaller scaled clusters of 1,000 accelerators to potentially 30,000 plus for much larger jobs. Each of these configurations as well as the accelerator that we utilize will require a slightly different approach to hardware and network systems designs."
For AI training, the servers are "built around accelerators and the network system operating as one," he continued. "This also enables efficiency in our fiber deployment, because we need a significant fiber to interconnect these servers. So colocating them closer together will allow us to gain some efficiencies there."
GPUs require much more power than CPUs (and therefore more cooling), something Meta's previous data center design could not support.
"These servers are going to require different types of cooling," Duong said. While the high-density GPUs will need liquid cooling, Meta will still have a large amount of traditional workloads that can exist on CPUs, which can still use air cooling.
The facility as a whole will use water cooling, but it will only be used for the air handling unit on the majority of servers. A growing number of AI training servers will instead get water from a cooling distribution unit, and then direct-to-chip. Some of this cooling infrastructure is the USystems ColdLogik RDHx, DCD understands. One image shared with DCD appears to show some form of immersion cooling, but Meta made no mention of it during its announcement - DCD has contacted the company for clarification.

"We're gonna only deploy a small percentage of liquid to chip cooling on day one," Duong said. "And we'll scale it up as we need. This means more complex upfront rack placement, and planning - we haven't had to do that in the past. So this is a very complicated process for us, but it allows us to save some capital."
He also admitted that "future proofing requirements for both air and water cooling doesn't do us any favors in power efficiency or reducing costs or deploying data centers faster. So we had to make some tradeoffs as we progress through the design."
One potential tradeoff is that the company will use fewer diesel generators and other physical resiliency, and instead rely more on software resiliency and some hardware buffer. "But this means that we're going to take on some unknown risk associated with software for our AI workloads," Duong said. "We're still learning about that, as we're deploying this in scale. And so as we learn more, we might adjust our strategy."
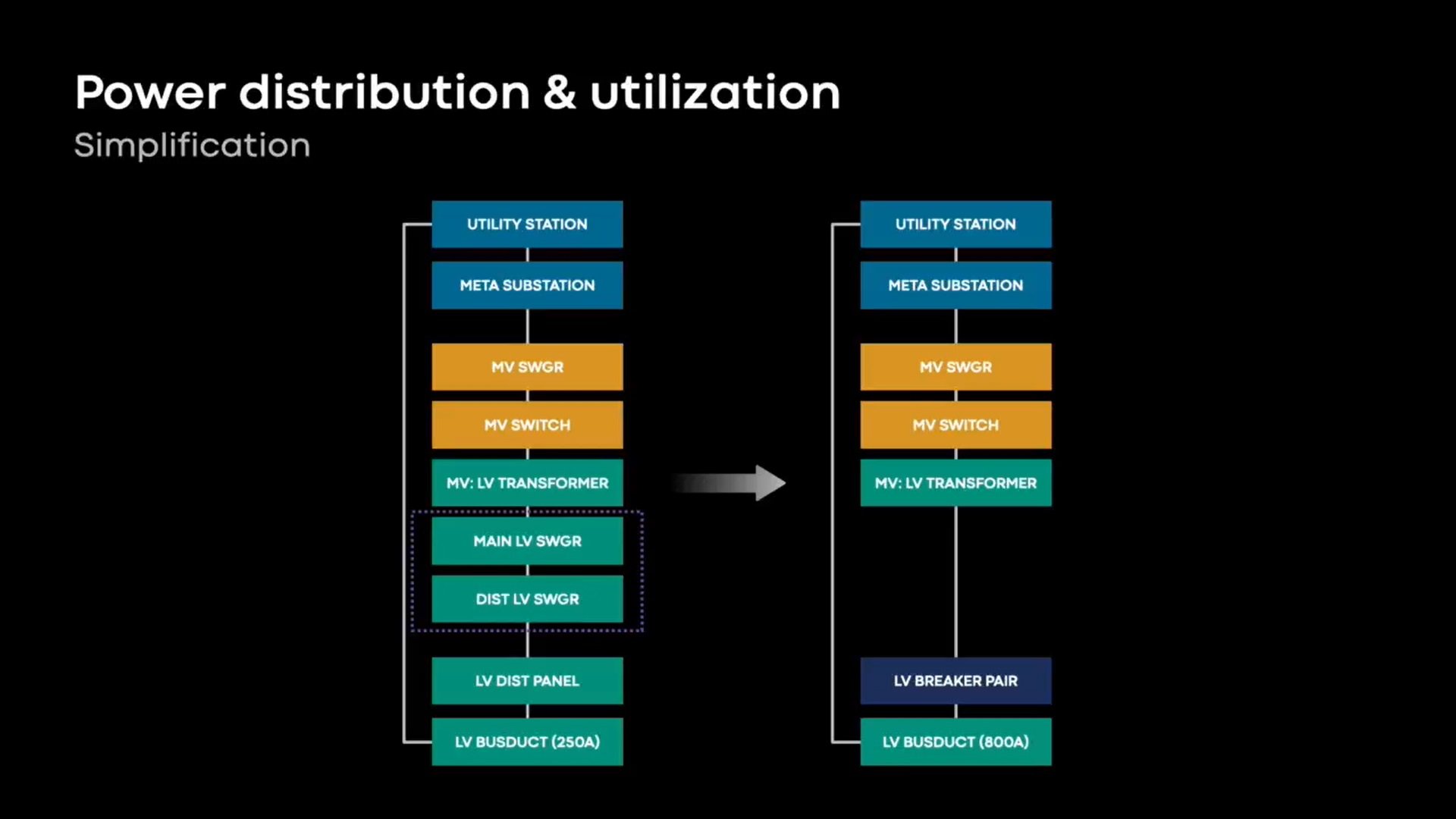
The new design also delivers power infrastructure closer to the server rack, Duong said. "It will be simpler and more efficient with our new design. We're eliminating as much equipment as possible through our power distribution chain... we're eliminating the low voltage switchgear, that creates a bottleneck of capacity.
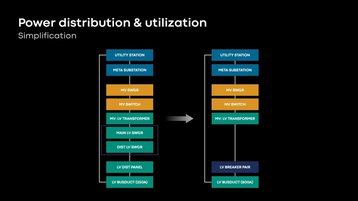
"Eliminating that allows the server rack to grow in density in the future with minor modifications to our infrastructure, and it continues to allow for greater power utilization."
The company claims that its current data centers utilize roughly 70+ percent of the power it deploys, but did not say what its new designs will reach.
Overall, the company anticipates that its next-gen data center will be 31 percent more cost-effective. "And we're gonna be able to build it two times faster for a complete full region, when you compare that to our current generation data center," Duong said.
Meta's supercomputer
Outside of the core design for its future standard data centers, Meta has operated the 'AI Research SuperCluster' since early 2022, itself an upgrade on a previous supercomputer.
The RSC has now been upgraded with nearly 10,000 Nvidia V100 Tensor Core GPUs, for a total of 16,000. The company said that it also built a custom storage engine, in partnership with Penguin Computing and Pure Storage.
The RSC is based on 2,000 Nvidia DGX A100 systems, connected via an Nvidia Quantum InfiniBand 16 Tb/s fabric network.
There were "a few lessons that we learned and we incorporated into the second phase of the cluster," Meta software engineer Kalyan Saladi said. "Number one is failure rates. The hardware failure rates were higher than we anticipated, and this required us to build better detection remediation mechanisms to ensure a stable and reliable cluster and offer a seamless experience to our researchers. Next up, our fabric - one of the largest flat IP fabrics in the world, especially at this scale - forced us to do pioneering and groundbreaking work to find the performance bottlenecks, tune, and sustain the performance of the cluster over a long period of time. And these lessons were incorporated into how we brought up the rest of the cluster in phase two."
The company also made it easier for teams to run multiple projects on the RSC at the same time.
"Why build a custom Super Cluster instead of using the existing data center technology that Meta has deployed all over the globe?" Saladi asked.
"It really comes down to understanding and realizing the unique demands large-scale AI training places on the infrastructure. This translates into our need to control the physical parameters," Saladi said.
"Number one is cooling technology. Airflow-based cooling was not meeting the mark for large-scale AI training for us. So we had to go with liquid cooling, which was a departure from Meta production data centers. Given the rack density, given the number of GPUs we wanted to pack in the data center building, this meant that the power requirements significantly deviated again from the production setup. But there is one more important aspect, and that is the specialized flat back-end network. This is a low latency high bandwidth network with constraints on the physical parameters of how far you can spread these GPUs. When you put these three together, we had to make a choice that we needed a custom cluster."

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Meta's chips
While its first foray into AI semiconductors did not go to plan, Meta hopes that it will build its own chip (similar to Google's TPU, AWS' Trainium, and Microsoft's Athena).
The Meta Training and Inference Accelerator (MTIA) chip hopes, as the name suggests, to handle both AI workloads. The semiconductor is based on the 7nm process node, and is fabricated by TSMC.
It runs at 800 megahertz, is about 370 millimeters square, and has a small power budget of 25 watts. It provides 102 Tops of Integer (8-bit) accuracy computation or 51.2 teraflops of FP16 accuracy computation.
Amin Firoozshahian, Meta infrastructure research scientist, said: "It's a chip that's optimized for running the workloads that we care about and tailored specifically for those needs."
It is designed in particular for PyTorch, an open-source machine learning framework initially launched by Meta. Alongside announcing the new chip, the company detailed PyTorch 2.0.
In addition to the MTIA, the company has developed the Meta Scalable Video Processor (MSVP).
"MSVP processes video nine times faster than the traditional software encoders - the same video quality at half the energy," Harikrishna Reddy, the project's technical lead manager said.
"MSVP raises the bar on frame resizing quality, video encoding quality, and we are the first in the industry to support objective quality metrics in hardware. So for every video encode we do, we also compute a quality score using standard metrics like SSIM, PSNR, or MSSIM. And then we use this quality score to indicate how this video will be perceived when a user sees it on the video. Imagine doing this at scale across billions of videos."