Less than a week after a Google Cloud network outage that brought services like multimedia messaging app Snapchat down, Facebook's messaging platform WhatsApp experienced an outage.
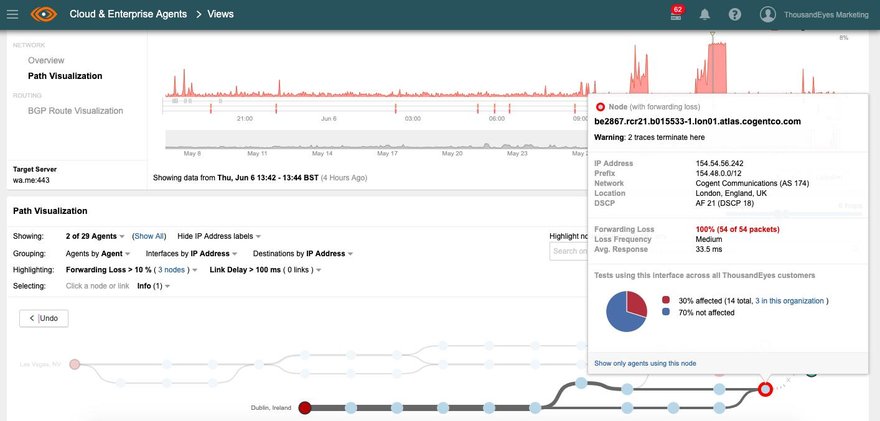
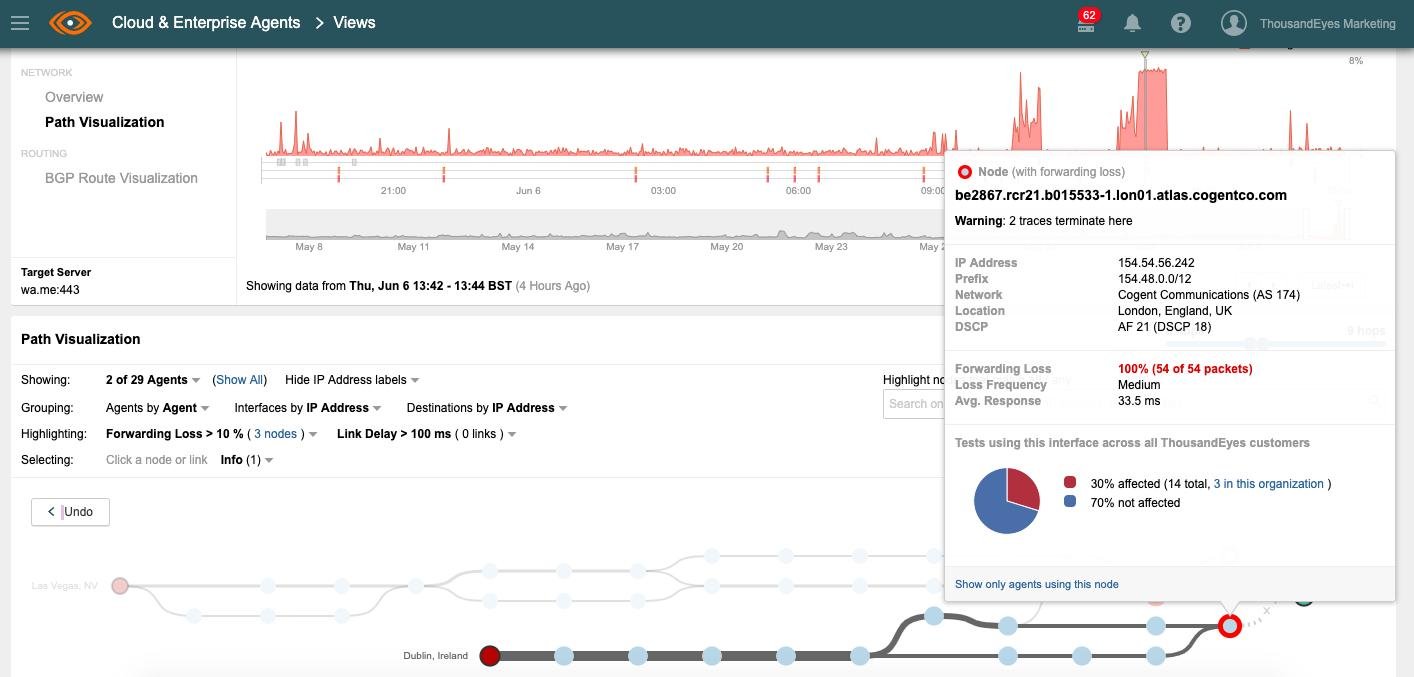
Network monitoring company ThousandEyes blamed the short outage on packet loss within Cogent’s London data center. WhatsApp, as well as Facebook and Instagram, suffered a much larger outage in March, with the platforms down for some 14 hours.
Update: For an analysis of what happened, go here.
Cogent analysis
"Users from multiple locations around the world who were attempting to access WhatsApp were unable to from 10:50am - 11:30am BST and from 1:10pm - 2:13pm BST. ThousandEyes picked up the outages and identified the issue to 100 percent packet loss within Cogent’s London data center."
Cogent Communications operates 52 data centers in North America and Europe, including the one at 20 Mastmaker Court, E149 UB, London.
The company also operates over 57,400 route miles of long-haul fiber and more than 33,600 miles of metropolitan fiber serving over 820 metropolitan rings.
Earlier this week, Google's VP of 24x7, Benjamin Treynor Sloss, provided insight into his company's outage: "In essence, the root cause of Sunday’s disruption was a configuration change that was intended for a small number of servers in a single region. The configuration was incorrectly applied to a larger number of servers across several neighboring regions, and it caused those regions to stop using more than half of their available network capacity.
"The network traffic to/from those regions then tried to fit into the remaining network capacity, but it did not. The network became congested, and our networking systems correctly triaged the traffic overload and dropped larger, less latency-sensitive traffic in order to preserve smaller latency-sensitive traffic flows, much as urgent packages may be couriered by bicycle through even the worst traffic jam.
"Google’s engineering teams detected the issue within seconds, but diagnosis and correction took far longer than our target of a few minutes. Once alerted, engineering teams quickly identified the cause of the network congestion, but the same network congestion which was creating service degradation also slowed the engineering teams’ ability to restore the correct configurations, prolonging the outage. The Google teams were keenly aware that every minute which passed represented another minute of user impact, and brought on additional help to parallelize restoration efforts."



{kind=link}