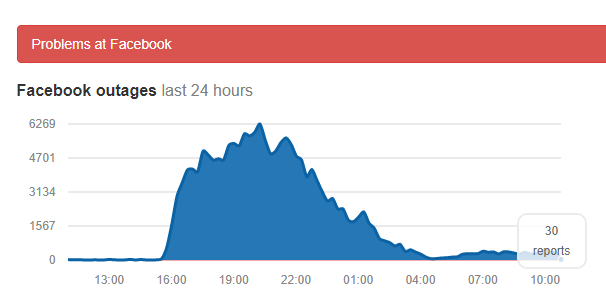
Facebook has suffered one of the most sustained outages in the its history. The cause of the 14-hour problem remains unknown, and issues continue with Facebook, Instagram, WhatsApp and Messenger.
The trouble began around 9:00 PDT on 13 March and continues to affect some services today (14 March). The cause remains a mystery but appears to be with the application software. A tweet from NBC journalist Raj Mathai blaming "database overload" has no corroboration, and earlier reports pointing to a leak of BGP Internet routing data (similar to the cause of last year's Google Cloud outage) have been ruled out.
Downer
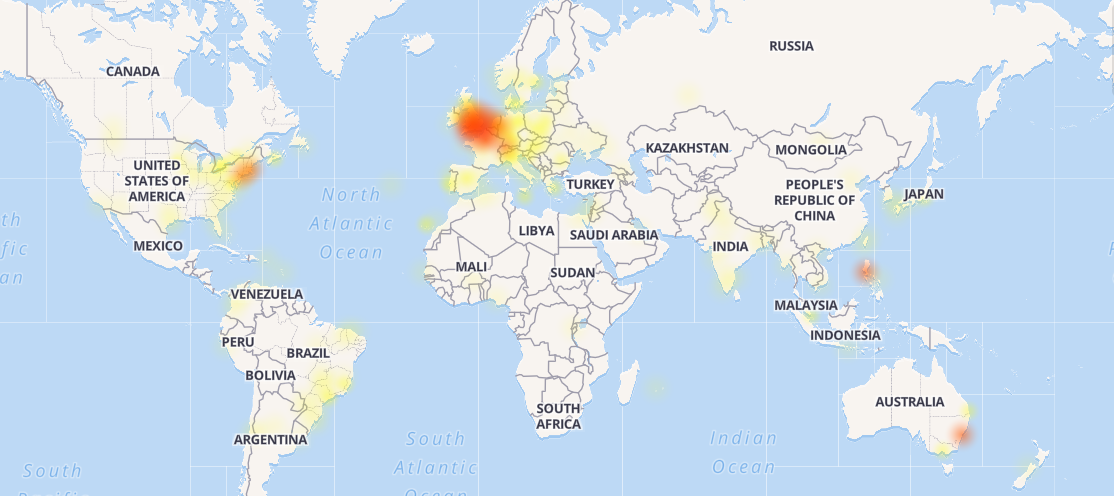
Reports from DownDetector suggested that the problem was global, and peaked between 9:00 and 15:00 PDT for all three services, before tailing off, though there are still residual reports of problems with all three applications.
Facebook announced two years ago that it was moving data from its WhatsApp acquisition from IBM's cloud to its own data centers. The fact that WhatsApp failed in step with the mother ship could be evidence that project was successfully completed.
"We're aware that some people are currently having trouble accessing the Facebook family of apps," Facebook said in a tweet. "We're working to resolve the issue as soon as possible." The company added that "the issue is not related to a DDoS attack."
Facebook has faced disruption before, but not on the same scale. In 2015, it went down twice in one week, but each outage was less than one hour, and the service only had 1.5 billion monthly users at the time, compared with today's 2.3 billion. The previous year, in 2014, a botched software update took it out for 2.5 hours, and in 2010, a database problem disabled it. It has been down for a longer period, but that was in 2008 when the site had less than 150 million users.
Respected network firm Netscout has scotched earlier reports of a BGP error. Last night, various outlets reported that Netscout had found evidence of a leak of BGP routing data, but Roland Dobbins, a Netscout principal engineer, told Ars Technica's Dan Goodin that this was an internal "miscommunication" which resulted in an erroneous email being sent to journalists:
Roland Dobbins, principle engineer at Netscout's Assert team, says he has no data whatsoever to support the claim that a BGP leak is the cause of today's Facebook or Instagram outages. "There was an internal miscommunication here," he says of the email PR people sent to reporters
— Dan Goodin (@dangoodin001) March 13, 2019
The outages have also affected Facebook's ad-buying system, several brand marketers have tweeted about the issue. Facebook said that it is investigating the overall impact of the outage "including the possibility of refunds for advertisers."
2019 sales estimates put Facebook's daily ad revenue at $250 million/£189m, so any downtime for ad sales will be costly.
Network monitoring company ThousandEyes said: “The cause would appear to be internal rather than a network or Internet delivery issue - for example we saw '500 internal server errors' from Facebook. Given the sheer scale and continuous changes that these web scale providers are constantly making to their applications and infrastructure, sometimes things break as a result of these changes, even in the most capable hands.
"When investigating Facebook’s issues today, we’re not seeing any BGP changes that are affecting connectivity, packet loss or latency. Since Facebook uses its own backbone network, it’s not clear/we don’t have insight as to how an external transit route issue would cause a disruption within the internal Facebook network.”
In an effort to minimize the chances of an outage, Facebook has a team working on 'Project Storm,' which stress-tests data centers with various tests and drills, including turning off a data center entirely.



{kind=link}
{kind=link}