
If you haven’t considered how risky it is to rely on the Internet to carry your mission-critical customer and employee digital experiences, then the month of June 2019 alone can serve as a great learning opportunity, with three distinct and far-reaching examples of just how fragile the Internet is.
On June 2, we saw a major Google outage that lasted for four hours, affecting access to various services including YouTube, G Suite and Google Compute Engine. On June 6 a route leak from a European hosting provider caused traffic destined for the likes of WhatsApp to reroute through China Telecom and get dropped in the process. And now, for roughly two hours between 7 a.m. and 9 a.m. ET on June 24th, ThousandEyes detected a significant route leak event that impacted users trying to access services fronted by CDN provider Cloudflare, including gaming platforms Discord and Nintendo Life. The route leak also affected access to some AWS services.
Following is a breakdown of what we observed, reflections on the state of Internet routing, and thoughts on how external visibility can help minimize the effect of outages on your business.
What we saw
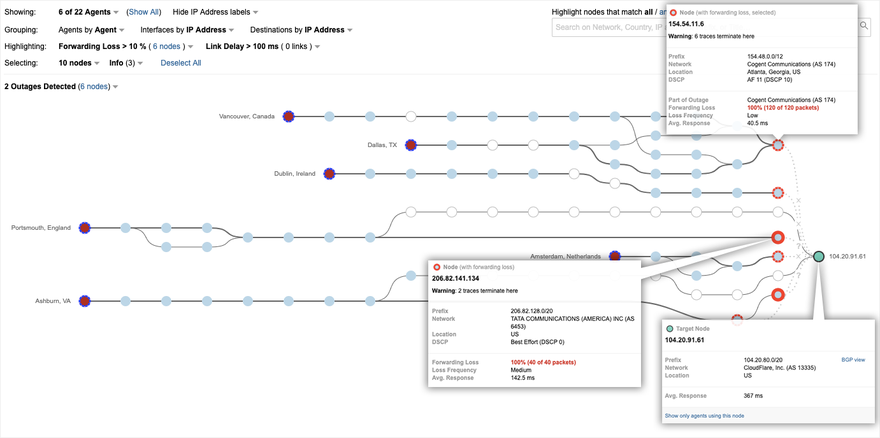
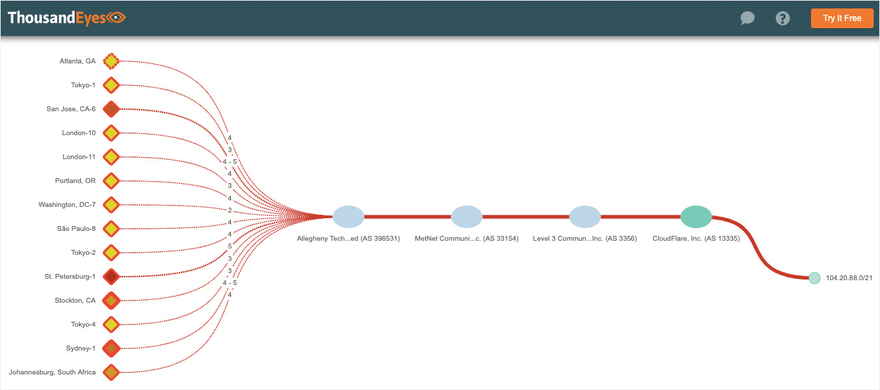
At around 7 a.m. ET, ThousandEyes detected impacts to multiple applications and services around the world. Figure 1 shows an application that is being served by Cloudflare on the right (via Cloudflare CDN edge IP address 104.20.91.61), with user locations on the left in the U.S., Canada and UK experiencing severe packet loss when trying to reach the application. The red nodes on the right indicate that packets destined for 103.20.91.61 are getting dropped in transit to Cloudflare. 100 percent packet loss at those nodes indicate significant congestion on the forwarding plane of the network. The question is, why? Was this an issue within Cloudflare’s network or was the source of the problem elsewhere?
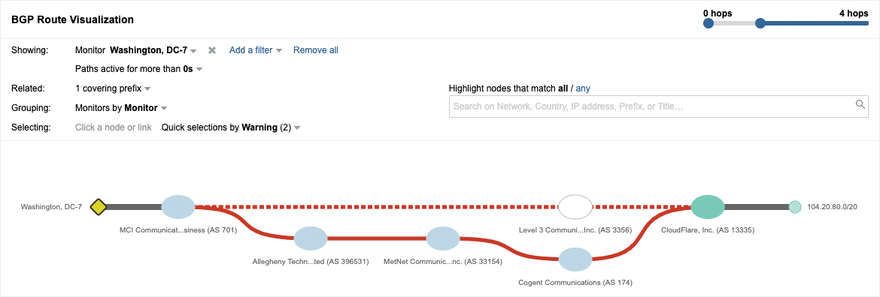
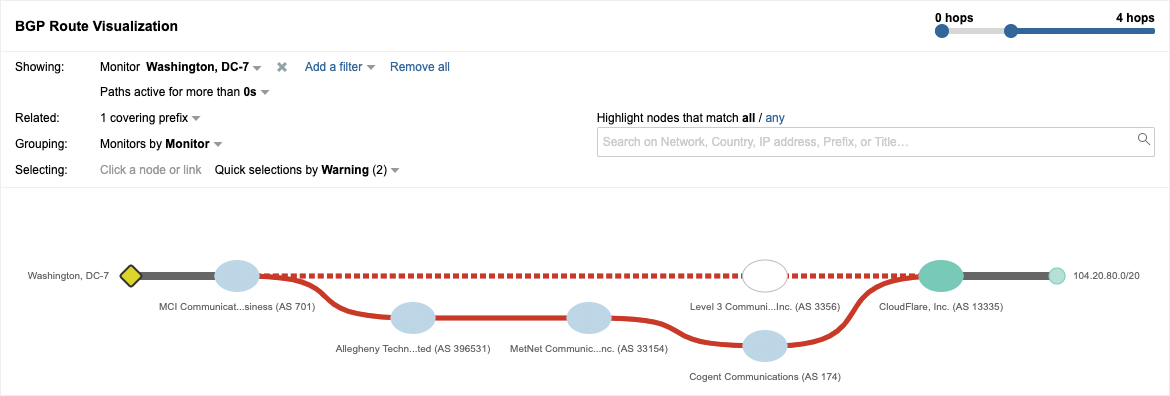
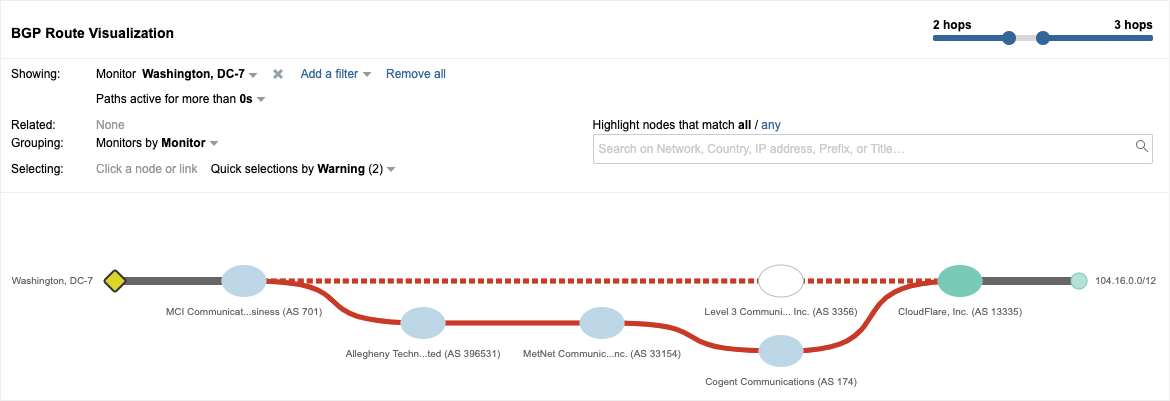
By drilling into the BGP view that is time-correlated with the Path Visualization in Figure 1, we saw an interesting phenomenon. The Cloudflare-announced Internet routed prefix 104.20.80.0/20 that includes the IP address for this service had experienced an odd path change, as seen in Figure 2. The normal path from left to right is shown on the top portion of the visualization, going through Verizon AS 701 (formerly MCI Communications) and Level 3 Communications AS 3356 to reach Cloudflare AS 13335. However, the red dotted line indicates that a change occurred and that this path is no longer in use. In the bottom part of the visualization, we can see a newly introduced AS path from left to right from Verizon through Allegheny Technologies AS 396531, DQE (formerly MetNet) AS 33154, and Cogent Communications AS 174 to Cloudflare.
The solid red line indicates that this is the path that has replaced the dotted line path.
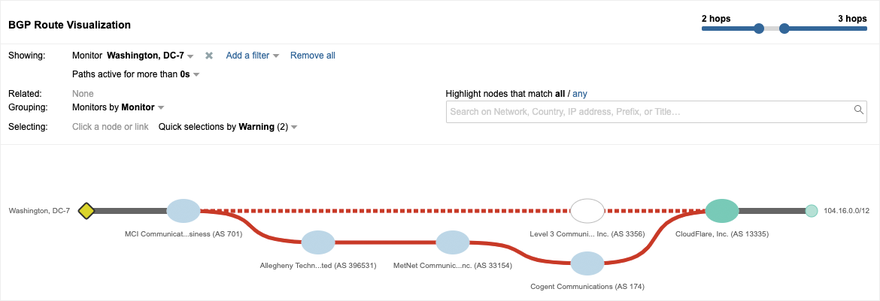
What’s odd about this path is that Allegheny Technologies isn’t a transit provider that you’d expect to be in any path between Verizon and Cloudflare. In fact, Allegheny isn’t an ISP at all, but rather a global metals manufacturer. Moreover, this /20 wasn’t the only route being impacted. Figure 3 shows another Cloudflare prefix, 104.16.0.0/12 with the same path change at the same time. A /12 prefix represents roughly a million IP addresses, so the scope of IP address space being rerouted was non-trivial. As we looked further, we could see that a variety of other Cloudflare prefixes were getting rerouted. This looked more and more like a route leak event.
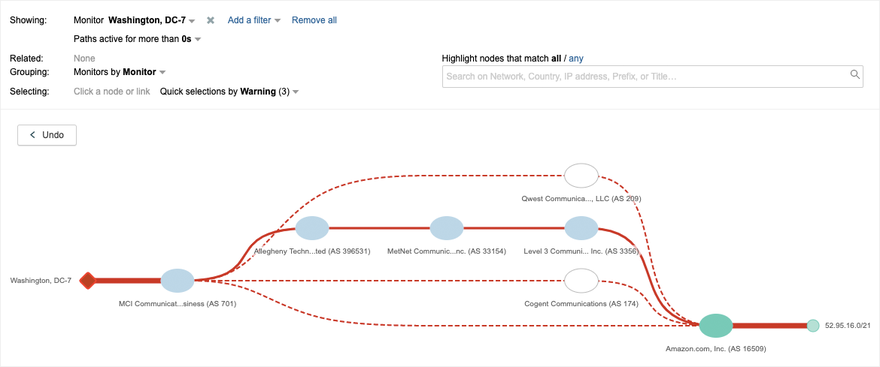
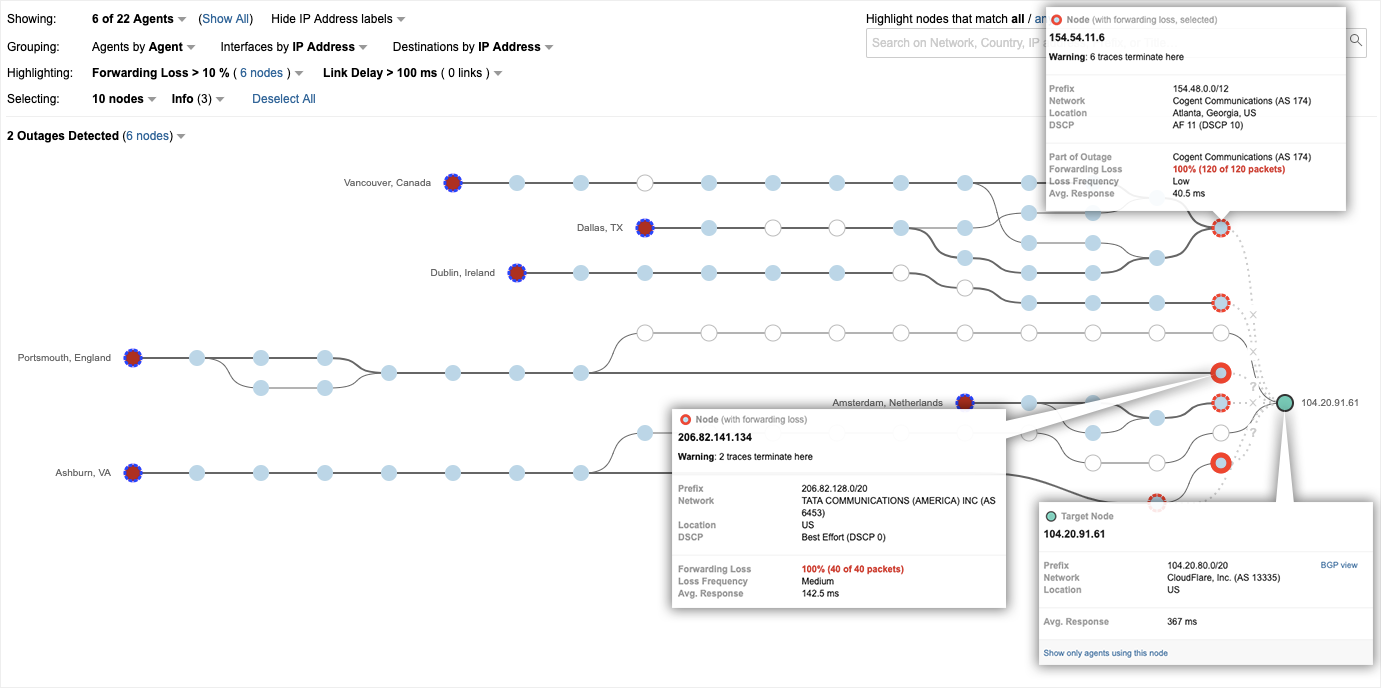
While investigating this routing anomaly, we further saw that the suspected route leak had also impacted AWS, with the same players in the new path. Figure 4 shows a route to a prefix in the AWS East-2 Ohio region changing from Verizon through Qwest (Now CenturyLink) on the top to the new route including Allegheny and DQE shown in the middle of the visualization.
At 7:36 a.m. Cloudflare’s status page announced that they had “identified a possible route leak that was impacting some Cloudflare IP ranges.” Other industry observers also weighed in with this same assessment, that a large scale route leak had occurred, with some reporting that up to 20,000 routes were leaked.
More specific routes
But then we also noticed something more interesting than a garden-variety route leak. The leak included the introduction of dozens of more-specific routes to pre-existing, legitimate Cloudflare routes. For example, Figure 5 shows prefix 104.20.88.0/21, which is part of Cloudflare’s address space and that was newly announced at the time of the other route changes.
However, this address space had already been advertised as part of a larger (less specific) prefix which we saw above–104.20.80.0/20. When a more-specific prefix is advertised to the Internet, its route is preferred to the less specific prefix. Advertising a more-specific route for a third party’s network is generally a no-no. In fact, intentional advertising of a more-specific prefix is a BGP hijacking method—how criminals attempt to siphon traffic away from legitimate service hosts for cyber-security exploits. These more-specific routes didn’t appear to be malicious, especially because it wasn’t apparent what a metals company would want with Cloudflare traffic, but it was definitely unusual to see multiple more-specific routes in the mix.
Whodunnit?
At this point, we knew that we had a particularly interesting route leak that included what appeared to be non-maliciously advertised more-specific routes. The next question was, where did this route leak come from? Looking into our route leak detection data told us that the first instance that the wider Internet (or Default Free Zone — DFZ) was exposed to the route leak was based on advertisements from Allegheny to Verizon.
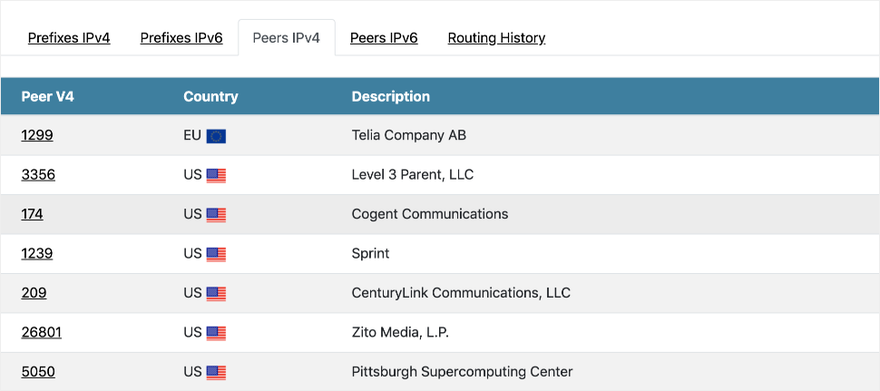
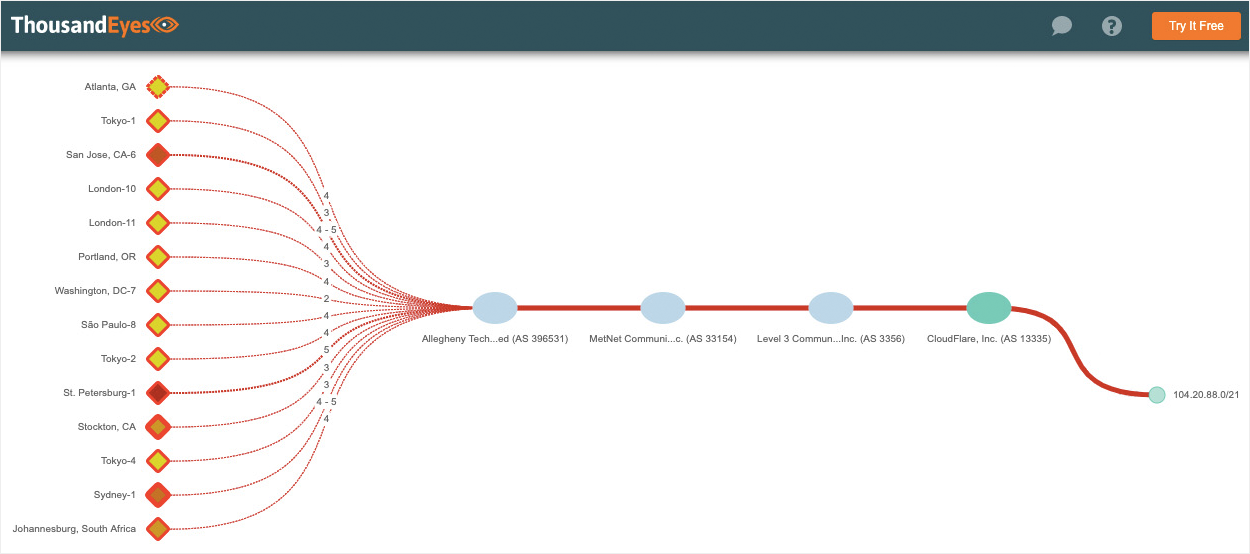
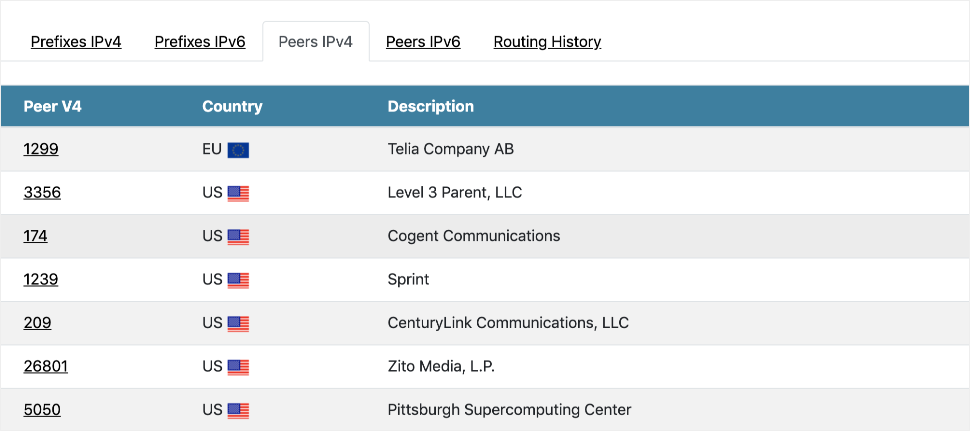
However, Allegheny AS 396531 as the original source didn’t make a lot of sense. Allegheny isn’t an ISP, has only two upstream transit providers–DQE and Verizon–and only advertises a single /24 prefix. Essentially, AS 396531 is a corporate eyeball network. The scope of the route leak didn’t match their profile. Furthermore, there was no imaginable reason why Allegheny would generate a bunch of /21 more-specific routes to Cloudflare. Since the route leaked prefixes went to Verizon, we turned our attention to Allegheny’s other upstream provider, DQE. DQE AS 33154 is a regional ISP peered with several Tier 1 ISPs, as seen in Figure 6 below, which makes them a Tier 2 transit provider, so they made more sense as the original source of the route leak.
But what about those more-specific prefixes? One scenario where non-malicious, more-specific routes can be created is when a transit provider is using route optimization software to help load balance traffic across its backbone coming from Internet sites through its transit provider peerings and headed toward its downstream customers.
The reason for doing this is to improve the efficiency of backbone link utilization to avoid over-saturating some links and reduce the need for immediate capital investment upgrades, to optimize usage and costs of multiple transit links and to improve performance to customers. In this case, that could have meant dividing /20s into /21s to provide greater routing granularity for route optimization and load balancing purposes.
Unfortunately, if those routes get out into the wilds of the Internet (for example, via an error that externally leaks them), they can cause considerable havoc. Which is why some Internet experts are extremely critical of BGP route optimization software and the risks it poses to Internet routing integrity. In fact, Job Snijders from NTT wrote a scathing op-ed on this topic back in 2017, including this assessment:
Given the peering relationship between DQE and Allegheny, as well as the scope of the route leak and the presence of more-specific third party prefixes likely generated for route optimization, we believe DQE is likely the original source of the route leak. DQE appears to have advertised these leaked routes, including the more-specific Cloudflare routes, to Allegheny, which in turn propagated the routes through Verizon to the rest of the Internet.
The end result was that a huge set of user traffic headed toward Cloudflare and other providers got routed through a relatively small corporate network, with predictable results. Massive congestion from the traffic redirection led to high levels of packet loss and service disruption. Users simply weren’t able to reach the Cloudflare edge servers and the apps and services that depended on them. Cloudflare shared that at its peak, the route leak event affected about 15 percent of its global traffic.
Who propagated it?
Route leaks happen fairly regularly. Routing is complicated. Humans make configuration errors, as we saw with the MainOne Nigerian ISP route leak that caused the global rerouting of some of Google’s traffic. And sometimes automation systems can trigger service disruptions, as we saw in the recent Google outage.
While Allegheny can’t really be blamed for accepting routes from its upstream transit provider, it suffered a process breakdown in that it propagated these routes to Verizon. But that’s where the more consequential issue of routing hygiene comes into play. The fact that Verizon accepted and propagated a huge set of leaked routes from a downstream enterprise eyeball network turned what could have been an isolated issue into a significant outage.
There has been some heated commentary on this topic from Cloudflare and other Internet observers, who have commented that Verizon should have caught this issue with one of multiple possible filtering mechanisms. Those critiques are more than fair on their face. For example, one long-standing route filtering practice is limiting the maximum number of prefix advertisements that will be accepted from a peer and shutting down the peering session once that threshold is breached. Another standard practice is filtering based on the Internet Routing Registry (IRR), which means a provider will only accept routes from a peer that are registered in the IRR. As for the more-specific routes, utilizing the Resource Public Key Infrastructure (RPKI) would have allowed Verizon to detect that the more-specific /21s were illegitimately advertised for Cloudflare and refuse to accept those routes from Allegheny.
But the issue of Internet routing hygiene goes beyond Verizon. We have often seen large providers accept and propagate route leaks from smaller providers that in some cases lead to application and service outages. There is a need for greater adherence to routing and IP addressing best practices on the Internet. The conundrum of the Internet is that it is a voluntary network. BGP routing is based on implied trust. Best practices aren’t enforced in any way except by peer pressure (pardon the pun) and market demands. There are some great community efforts to drive adoption of routing best practices, such as the Mutually Agreed Norms for Routing Security (MANRS), which is a global initiative supported by the Internet Society, that focuses on crucial fixes to Internet routing practices. At this moment, there are only 163 network operator and 32 IXP participants in MANRS.
Enterprises and other organizations who are purchasing transit services from ISPs can play a part in driving adherence to Internet routing best practices by stating them as requirements in their contracts. Even if in some cases it isn’t possible to keep those clauses, repeated encounters with those requirements will inform providers that they need to up their routing hygiene game and provide market incentives for them to do so.
Visibility is crucial in an unpredictable internet
It is sometimes tempting to think of outages as phenomena you simply have to endure fatalistically. But that would be a generally wrong conclusion. True, there are cases where an outage is just so big that you need to let the major Internet and cloud players sort it out. However, for every massive global outage, there are many smaller-scale cloud and Internet outages that can affect your business, and for which there is often a remedy—if you can see what’s going on. For example, ThousandEyes regularly detects ISP traffic outages of small to medium scale that disrupt business-critical applications and services.
For many of those issues, there is a remedy available: contacting your provider and getting their help to route around the issue. And let’s not forget that SaaS, security and other cloud providers can suffer their own mini outages. Being able to figure out whether an issue is due to something in your network, in the SaaS or cloud provider or in an ISP, and whether its a DNS, network, server or application-layer issue is critical to getting a remedy.
In an era where your business is increasingly dependent on a growing ecosystem of cloud providers, connected by a highly unpredictable Internet, visibility beyond your four walls is a must.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}