{kind=link}
When parallelism in processors was first introduced, marketers explained it as “just like having two processors on one chip.” Few statements could have been more false. Whenever you delegate a job to a group, the first problem appears to be dividing up the responsibilities. In practice, this ends up being the second problem; the real first problem becomes “making sure everyone’s on the same page.”
Chip architects describe this problem with, literally, the same words. The “same page” in the context of processors is the cache — the batch of high-speed memory that copies pages of lower-speed DRAM. Intel processors tend to include shared caches, but at the lowest level, each core has its own. As with any multi-user database, the trick is to enable every user to see the most current and accurate copy of the data; if one user changes the data, that change has to eventually be reflected in every other user’s view of it.
Cache incoherence
There are plenty of mechanisms for achieving this level of accuracy with processor cores, for what’s called cache coherence. The problem with most of them is that, when the size of your core stack grows, the complexity of each mechanism increases. Soon, whatever time was saved by having caches in the first place is more than usurped by time spent keeping the caches in order, and the more cores you have, the slower the processor becomes.
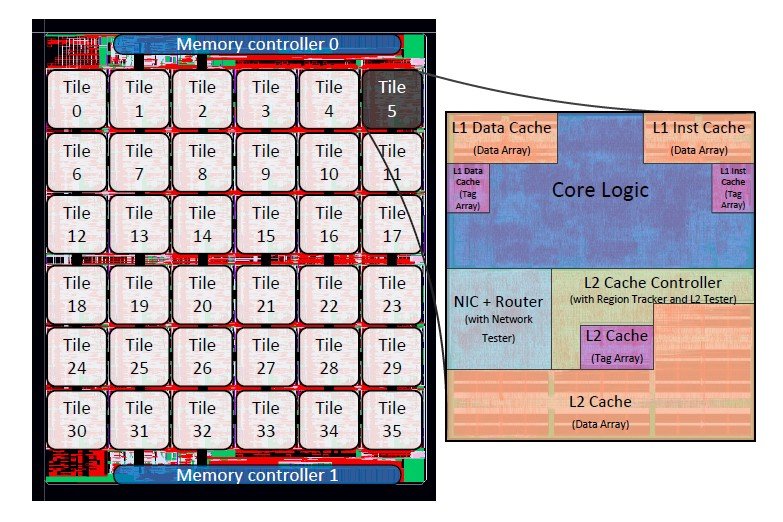
Researchers at the Massachusetts Institute of Technology (MIT) are attacking this problem by applying a kind of Internet-style architecture to a network of cores: one where messages from one cache are broadcast in the general direction of all the others, and routers of a sort direct those messages where they need to go. If network coherence works for cloud databases of thousands of simultaneous users, maybe it can work for a microchip database of 36.
The name for this new MIT approach at once conjures up memories of Charles Schulz’ “Peanuts” strip and the movie “Dirty Harry:” SCORPIO stands for Snoopy COherent Research Processor with Interconnect Ordering, and core architects are already well-accustomed to the phrase “Snoopy coherence.” It’s actually one of the simpler forms of cache coherence, which experts had actually suggested should be abandoned as the core count continued to rise.
“Snoopy,” in this case, refers to the attitude of the caches with respect to each other — always listening in. Each cache listens to the bus to see if a write request for a datum refers to an address on one of the lines it’s holding. If some other cache is writing to such an address, it sets a flag invalidating its own copy of that datum. This causes any future read request to trigger a miss, resulting in a pass through to DRAM, and a refresh of the entire cache with the contents of the page at that DRAM address.
One solution becomes a problem
It’s an easy architecture to implement, supposing you had only four cores to deal with. When you have more, the typical architecture you might prefer involves a directory-based protocol such as distributed shared memory (DSM). Here, a chain of nodes containing the accuracy state of all address lines is strung throughout the system’s main memory. Before any read or cache refresh takes place for an address, the cache consults the node representing the state of that address’ page. It’s more complex than snoopy, but it doesn’t build up latencies as quickly.
At least, not for a handful of cores. But latencies increase exponentially as you get closer to 36 cores. And if you make each node refer to the state of larger blocks of memory, you might gain some scalability back, but you sacrifice performance.
The solution the MIT team is attempting, according to a research paper released Monday (PDF available here), is a kind of scalable mesh network where each cache literally contains a network router, a separate notification router, and a network interface controller — and yes, the researchers call it the NIC, just like on a WAN.
Time passages
While the team is trying several different routing algorithms, the principle to which they all adhere is this: A synchronous timing system provides for given “time windows” for cache coherence messages to proceed through the mesh. They don’t have to be sent in any order (thus, the different algorithms to see which may be best in the end); the caches’ NICs simply must guarantee that they’re all received by the close of each window.
The hope here is that the scalability of the system is burdened only by a factor equivalent to the square root of the total number of cores; so, for instance, a 64-core mesh may have only 33% greater latencies than a 36-core mesh, rather than exponentially greater.
The MIT team admits that its research design, from a production standpoint, isn’t anything that Intel or anyone else may want to fabricate soon. “While our 36-core SCORPIO chip is an academic chip design that can be better optimized,” the team writes, “we learnt significantly through this exercise about the intricate interactions between processor, cache, interconnect and memory design, as well as the practical implementation overheads.”