IBM has deployed a cloud-based supercomputer on its public cloud service.
In a blog post published this week, the company detailed Vela, an ‘AI-optimized, cloud-native supercomputer.'
{kind=link}
The system has been online since May of 2022, housed within IBM Cloud. The system is currently only for use by AI researchers at IBM Research.
“Vela is now our go-to environment for IBM Researchers creating our most advanced AI capabilities, including our work on foundation models, and is where we collaborate with partners to train models of many kinds,” the company said.
Big Blue noted it chose Virtual Machines over bare metal to provide greater flexibility and allow researchers to provision and re-provision the infrastructure with different software stacks as required.
The company said it devised a way to expose all of the capabilities on the node (GPUs, CPUs, networking, and storage) into the VM so that the virtualization overhead is less than five percent, which it said was ‘the lowest overhead in the industry’ it was aware of.
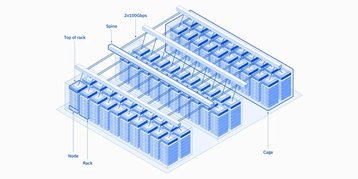
Each node includes eight 80GB Nvidia A100 GPUs, each with two 2nd Generation Intel Xeon Scalable processors (Cascade Lake), 1.5TB of DRAM, and four 3.2TB NVMe drives. The nodes are networked via multiple 100G network interfaces.
A diagram of Vela’s architecture suggests the system spans 60 racks; a second post featuring some of the company’s AI research described a system with a matching node set up and deployment date noted the system had 200 nodes.
“We can efficiently use our GPUs in distributed training runs with efficiencies of up to 90 percent and beyond for models with 10+ billion parameters. Next, we’ll be rolling out an implementation of remote direct memory access (RDMA) over converged ethernet (RoCE) at scale and GPU Direct RDMA (GDR), to deliver the performance benefits of RDMA and GDR while minimizing adverse impact to other traffic. Our lab measurements indicate that this will cut latency in half,” the company said.
Vela is natively integrated into IBM Cloud’s VPC environment, meaning that the AI workloads can use any of the more than 200 IBM Cloud services currently available. And while the work was done in the context of a public cloud, IBM said the architecture could also be adopted for on-premises AI system design.
The likes of Microsoft and Amazon are increasingly pitching their Azure and AWS platforms as a cloud-based option for supercomputing.
YellowDog previously created a distributed supercomputer on AWS, pulling together 3.2m vCPUs (virtual CPUs) for seven hours to analyze and screen 337 potential medical compounds for OMass Therapeutics. Managing performance of 1.93 petaflops, the machine was temporarily occupying the 136th spot in the Top500 list.
Microsoft currently has five Azure-based supercomputers in the top 50 of the Top500 list across facilities in the US and Europe. The 39.53 petaflops max Voyager-EUS2 system ranked number 10 when it debuted in November 2021. The Met Office’s next HPC systems will be located in a dedicated Azure data hall. The University of Bath has also opted for dedicated Azure-based HPC going forward.