
Every 10 years or so, the data center stares down the next big abstraction that inspires exciting new server operating system form factors. As Redmonk analyst Stephen O’Grady says in The Road to Abstraction: “Computers are hard, which is why it’s no surprise that one of the long running trends over the history of the technology industry is abstraction.”
With containers, there is near universal consensus that the newest unit of abstraction has officially arrived, beginning to supplant virtual machines. Containers are how developers now prefer to package up applications (a $2.7 billion market by 2020, according to 451 Research). This has far-reaching implications for how operators support those applications and the developers creating them. But there are some big differences between where we are today in the adoption curve of containers, compared to the last major abstraction shift in virtualization.
Let’s take a look at the implications that widespread container adoption will have for data center operators, where we are today, and what we learned from the previous shift to virtual machines.

Why are developers reaching for containers?
Containers are a developer insurgency – barbarians at the gate for data center operators. Shadow IT was the first iteration of this insurgency, where taking weeks to get a virtual machine provisioned internally led developers to just go to AWS and get servers directly with a credit card.
Now containers are allowing the same developers to move even faster. Because even on AWS, standing up a virtual machine takes minutes, and containers take milliseconds. As organizations prioritize shipping new products and features faster, to keep up in the software-eaten world, developers are favoring technology that allows them to scale applications and deploy resources much faster than what traditional VMs on public and private clouds can support. And the developer patterns at companies like Twitter and Netflix and other web-scale companies – where application and platform teams have autonomy over infrastructure – is starting to mainstream (for any development organization truly “moving fast”) as an Agile methodology best practice.
Unpack that a bit further, and you can see a variety of cost and performance benefits of containers over virtual machines, that help explain their rise in popularity. The first major benefit is the ability to run multiple applications on the same server or OS without a hypervisor eliminates the drag of the hypervisor on system resources, so your workloads have a lighter footprint – the container footprint is zero, because it’s simply a boundary of permissions and resources within Linux.
Containers fire up and decommission very rapidly compared to virtual machines – a perfect fit for the ephemeral nature of today’s short-lived workloads, which are often tied to real world events and “bursty.” And last but not least, the fewer dependencies of containers on the OS give more flexibility to deploying applications on different cloud providers and operating system, which play into organizational objectives of avoiding lock-in. And of course there is no VMware software license tax. That adds up to a lot of operating expense at any major data center.
But this is not playing out the same way it did for Virtual Machines
One of the distinguishing characteristics of the rules of containers is that there are no rules. The one constant is that the Docker container format has won out. But then technology choices and an abundance of fast-moving open source platforms abound. You can use whatever flavor of Linux you wish. You have your choice between rapidly-evolving container orchestration platforms such as Kubernetes, Mesosphere DC/OS and Docker Swarm.
Even at the container format level (presumed won by Docker), containerd is now challenging as a more open standard container format. So data center operators quickly find themselves in the deep-end with the many yet-to-be-standardized issues with provisioning container storage and networking, as well as run-time insights into containers that would rival the maturity of what operators have come to expect with virtual machines.
What it really boils down to is that the ability to operationalize containers is very uneven right now, for reasons of maturity of the ecosystem, and also user awareness.
There is no VMware of the container world. Essentially Docker is the closest thing we have to a universal brand for containers, but Docker is far from having a lock on the technology that VMware had in the early days of virtual machines. On the one hand, container early adopters have a lot of choices and flexibility, but it also means they have to be their own systems integrator and integrate a lot of these tools on their own. There is a MUCH higher bar to user enablement than simply attending a VMware enablement class and you’re “good to go”.
VMware had about five years completely on their own to create a market around virtual machines–from about 1997 to 2002. In this five year stretch they were the only game in town, and had a while to bake the technology, building enterprise grade guard-railing through things like VMotion, DRS resource balancing, etc.
Docker – on the other hand – nearly immediately open sourced its core technology around containers. Red Hat, Canonical, Mirantis and virtually every major open source vendor piled on with commercial support. So Docker was the first mover, but they lost control. And many would argue that it took them too long to emphasize orchestration, which is why they are behind both Kubernetes and Mesosphere DC/OS in Swarm adoption, despite having the massive first mover advantage of owning the container format.
Today’s container product ecosystem is one of the biggest data center land grabs we’ve seen in decades, with countless vendors vying to own various parts of the modern application “stack.” But with the freedom of choice and the plethora of available open source platforms, data center operators are also saddled by the challenge of choosing the right technology and being guinea pigs in highly customized integration. If you’re a web-scale giant like Netflix, Ebay or PayPal and have engineers to burn, the economics of containers makes sense. For the rest of the market that needs predictable outcomes, the waters can be pretty treacherous.
Where are we exactly today in container adoption?
{kind=link}
{kind=link}
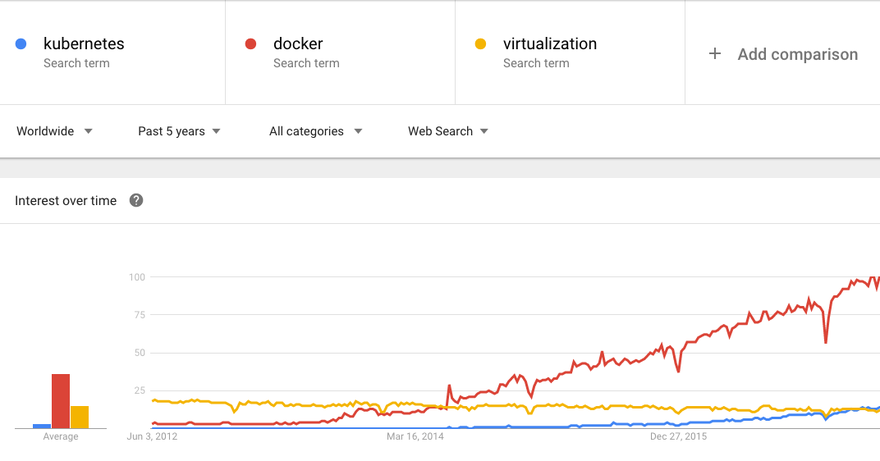
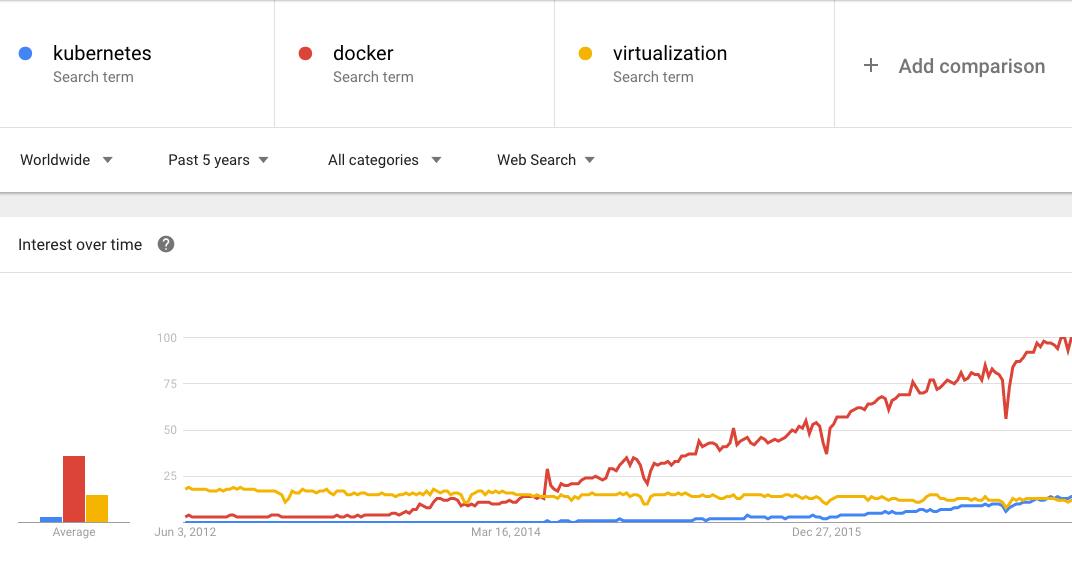
No one would dispute the attention that containers are getting. Docker itself has been on a nearly straight line up over the last three years in headlines, and Kubernetes is starting to reach a critical mass of interest as Google puts its weight behind it.
But where are we in terms of actual production adoption of containers? While I believe the net positives of containers are so exciting they will drive a sustained push until the point of ubiquity, what I’m hearing and seeing is that containers are generally still stuck in first gear, with popularity bound more to developer laptops, and few use cases that are reaching production deployment at mainstream enterprises.
Containers today: The Good
From my POV, the places where containers are predominantly seeing enterprise traction today include:
- Consumer-facing services moving to containerized, DevOps workflows (the more publicized production examples include big brands like Viacom, Bloomberg and Ticketmaster).
- Real time analytics with stateful apps and databases (Verizon, Google, Apple and Uber are among the mega brands who have gone on record with their case studies).
- Containers enabling end-to-end automated DevOps from microservices to databases.
Containers today: The Bad
In their push to mainstream, I’d argue there are two primary roadblocks that keep coming up:
- Containers’ own unsteady technology foundation: too many orchestration, networking, storage, security options. Infinite permutations. Unsupportable for typical enterprise (we’re not all Google or Facebook). With containers today, be prepared to throw people and money at the problem, but those people need more tools and support to succeed.
- Databases and analytics engines: the container ecosystem has struggled to meet requirements for persistent storage, automated scaling to keep pace with microservices, performance and latency to meet business expectations. Throwing money at the problem is the typical answer, which results in brute force with overprovisioning.
Containers today: The Ugly
While you can take a container and run it on a VM to take advantage of existing infrastructure, what we’re seeing is that end users doing this today (in the absence of mature container-specific production tooling) are experiencing the worst of both worlds–container tools complexity and vm overhead. The enterprises attempting this are typically going about it one of two ways:
- Simplistic model: One Container Per VM
- Easy to begin. Single network and storage mount per container (VM!). Existing tools work…to a point.
- But it gets hugely painful and expensive after a short while. VM sprawl. High waste/overhead. Storage and network mgmt is the old/slow/costly model dependent on the hypervisor. This approach creates a major disconnect in Dev vs Ops environment.
- Advanced model: Many Containers Per VM
- This creates immediate exposure to disparate network/storage models for containers. The VM abstraction doesn’t help address these.
- Most likely, you’re layering the new container stack atop the traditional IT model, which is what developers are pushing back on with their flight to public cloud.
Concluding thoughts for the data center operator
At this week’s CoreOS Fest (listen here from ~39:47 onwards) Ticketmaster’s Platform SVP shared a concern that’s become common to the early major production users of containers, when he said: “We don’t actually want to build any more software…The stuff that we don’t have to maintain, every piece of software that we write that should be commodity is a piece of technical debt we own forever.”
The early path on containers has been one of DIY, extreme customization, and technical debt. For the many organizations who view the upside of containers to be too great to wait-and-see, I’d offer a few key pieces of advice to reduce the risk:
- Give your customers (developers) what they want: container-native, automated experience for the entire application that offers easy scaling and management.
- Choose open source approach that reduces lockin and provides multi-support options. Presently the “stack” components that are playing nicest with openness includes Kubernetes, open APIs for Linux (network, storage so you can deploy apps on varying cloud infrastructure), CNI and Flex Volume.
- Don’t wait for solutions to mature - by then it’s too late. Dev will be in public cloud and ops will be the new mainframe, shrinking in the corner. It doesn’t require huge investment to build a modest container cluster with open APIs, and that’s the right starting point for most organizations.
Mark Balch is VP of products and marketing at Diamanti (formerly Datawise.io)