
Data center operators face escalating demand to provide advanced e-commerce shopping experiences, enhanced video streaming and generally better service while also being pressured to reduce or at least contain costs.
This is impossible to accomplish when the internal, non-revenue-generating networking tasks of today’s typical data center consume as much as 25 percent of its total server capacity. The problem only worsens as server and network speeds increase, rendering as much as half of today’s available server capacity unusable for the primary mission of delivering revenue-generating services.
A solution to this problem is application-acceleration technology that operates in user space rather than kernel space to reduce latency and increase transaction rates for the data center’s most network-intensive internal Transmission Control Protocol (TCP) applications.
The concept works on physical servers as well as in virtualized environments and is poised to remove billions of dollars of waste from today’s private and public cloud infrastructure investments. At the same time, the technology lowers total cost of ownership (TCO), increases peak application transaction rates to eliminate service “brownouts” and reduces network jitter with greater response times for superior quality of service (QoS).
Inefficiency of kernel-based networking
One of the biggest sources of inefficiency in enterprise, private and public cloud data centers is kernel-based networking. If the data center’s most network-intensive applications can be moved out of kernel space and accelerated in user space, they can be performed more efficiently and without burdening servers with all the associated CPU interrupts, context switches, lock contention and high number of memory copies.
This kernel-bypass concept has been proven with industry-standard POSIX sockets and deployed across x86-based bare metal, virtual machine or container platforms running Linux. Solutions that leverage the concept can be designed such that they retain compatibility with existing applications, management tools and network infrastructure, and do not require any rewriting or recompiling of the application or mandate that any new protocol be run on the wire.
This contrasts with Remote DMA (RDMA) acceleration protocols like RDMA over Converged Ethernet (RoCE), which requires special hardware on both ends of the wire or Internet Wide Area RDMA (iWARP) which requires TCP stack processing embedded in the Ethernet NIC ASIC itself. Unlike these RDMA solutions, Cloud Onload application acceleration on one end of the wire is interoperable with any TCP device on the other end of the wire, can be adapted easily as it is a software solution and requires no changes to the application software itself.
The choice of whether the application will run in user space or the standard Linux kernel stack can be made at run-time. The result is RDMA-like performance acceleration without requiring a forklift upgrade to the data center’s existing network infrastructure.
Application acceleration in user space also delivers big benefits in virtualized environments. Hypervisors that are configured for VM PCIe passthrough provide virtualized Linux guests with performance that is close to that of a bare-metal Linux kernel network. When used within a Linux guest in virtualized applications, it delivers the same acceleration benefits as adding Linux kernel bypass to hypervisor bypass and brings I/O latency down to two microseconds or less.
Improvement example
The Redis in-memory database (IMDB) is a prime example of an application whose performance can be significantly accelerated with the kernel-bypass approach. Like all IMDBs, Redis performance is heavily impacted by network I/O performance. Whenever a Redis instance uses server hardware storage or I/O resources, it must first invoke the driver for that resource. For kernel-based drivers (which make up the bulk of all I/O drivers), the application must make one or more calls to the operating system kernel to invoke the driver. Each of these calls results in a context switch during which the memory space of the application is put into system storage. These context switches consume significant amounts of system resources, reducing the amount of processing time available for Redis.
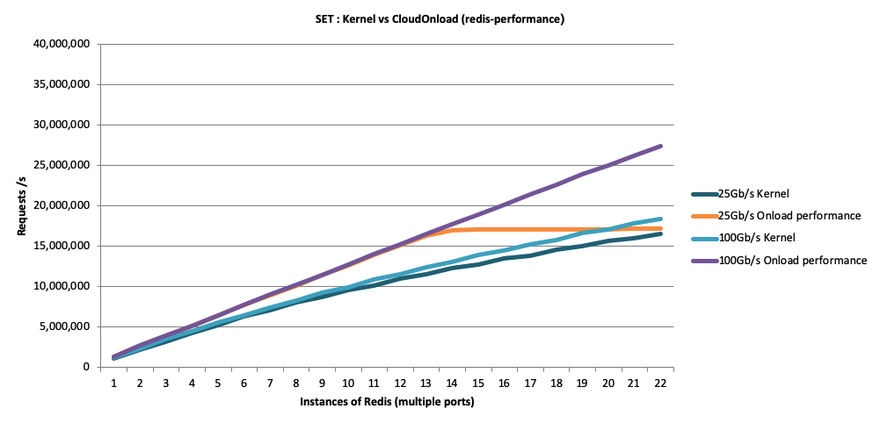
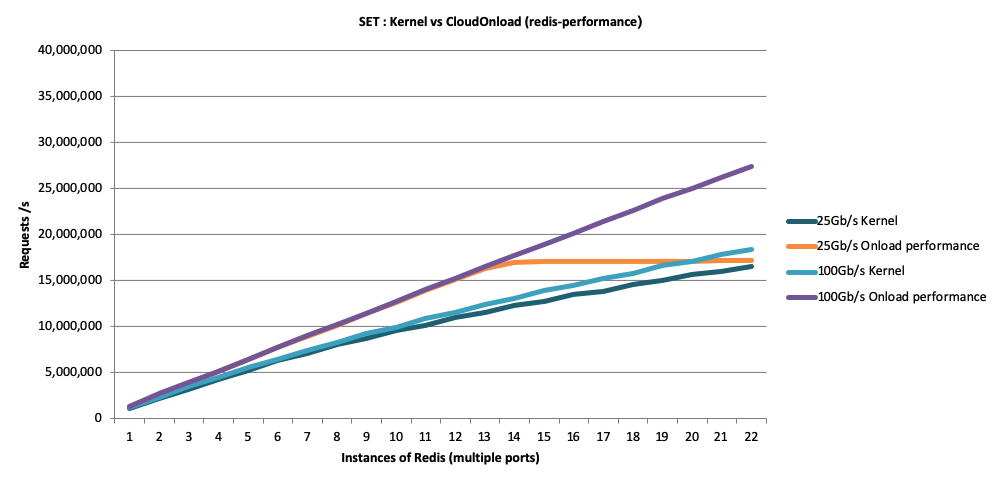
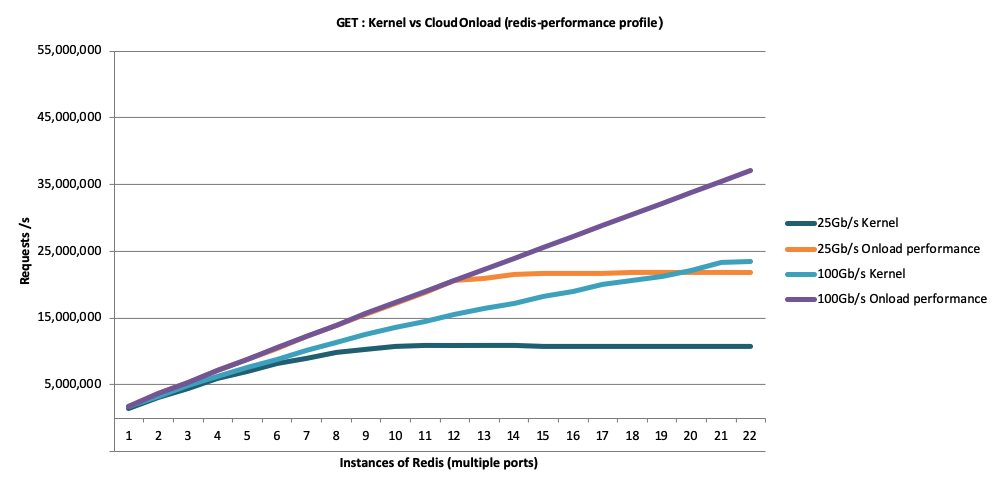
Figures 1 and 2 show benchmark test results for Redis SET and GET transactions against a Redis instance running on a typical dual-processor Linux server. All tests were run on the same network adapters at 10GbE, 25GbE and 100GbE speeds, with between one and 22 Redis instances. One set of tests was conducted using the standard Redis Ethernet stack while the second set used application acceleration with the kernel-bypass approach.
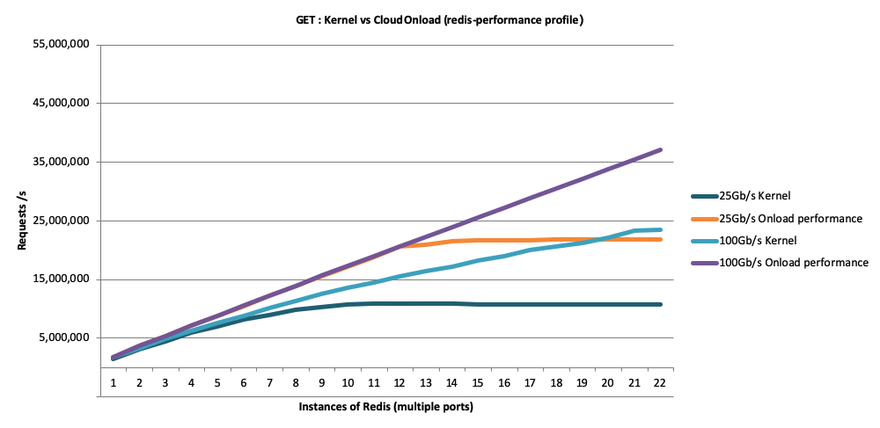
As these results show, bypassing the kernel with an application-acceleration solution allows Redis to completely “fill the wire” on both 10GbE and 25GbE networks, which the kernel driver could not achieve on a 25GbE network. At 100GbE speeds, the kernel-bypass solution enabled Redis to achieve 66 percent more performance than possible using the standard Redis kernel driver, which yields three benefits: 1) 66 percent more revenue using existing servers; or 2) the ability to cut capital expense (CapEx) and likely operational expense (OpEx) by more than 60 percent by using fewer servers; and 3) sustaining as much as 100 percent higher load at peak times.
In addition to Redis, kernel-bypass technology accelerates applications including software load balancers (NGINX, HA Proxy, Envoy), web servers (NGINX, Apache), application frameworks (Node.js, netty.io), other database servers like Couchbase and Memcached, message brokers like Kafka and Zookeeper, and storage applications. When properly implemented, kernel-bypass technology improves overall server performance from 2-10x while delivering the lowest latency jitter and maintaining very low CPU utilization.
With the advent of application-acceleration networking-based solutions that bypass the kernel, data center operators will have the opportunity to factor 25 to 50 percent fewer servers into their cloud data center buildouts.
This equates to a savings of approximately $100 million in capex and $25 million in OpEx per year for a typical deployment requiring 100k servers at the same time, the technology will contribute to significantly improved overall data center operation by reducing TCO while significantly increasing ROI, and by improving quality of service while eliminating brownouts during peak application transaction periods.



{kind=link}
{kind=link}