
The recent Eighth Annual Uptime Institute Data Center Industry Survey is, as ever, full of detailed findings about the data center industry, spanning the use of technologies, redundancy levels, rack density, staffing and skills, climate-change preparedness, and much more. It has generated publicity, discussion, and a few raised eyebrows. But even the most useful surveys throw up questions and doubts—perhaps about definitions, or sample size and make up, or bias, and sometimes about “linearity”—the ability to compare results from year to year. Sometimes, we see executives tying themselves in knots, trying to explain or justify odd or indefensible findings.
No one has taken issue with the Uptime Institute’s survey findings, but we have been looking at some headlines on the subject of outages. We find ourselves wondering if the data is right or if it really supports the apparently obvious conclusions. The survey showed fairly unequivocally that data center-related outages are common, and, apparently increasingly so, compared with previous surveys. But several people, including a few internally at Uptime Institute, have questioned this finding, perhaps because equipment, expertise, and management are so much more advanced than they were five or 10 years ago. How could failures possibly be more common?

There is a second debate, too: Has energy efficiency has been achieved at the expense of reliability? Energy efficiency has clearly improved over the past five years, as our PUE data shows, while reliability appears to have deteriorated. Does that mean the two are related? It is certainly possible, and some of the survey findings around infrastructure redundancy suggest as much. But we at Uptime Institute are not sure, and we did not link these questions together. Correlation, if it is that, is not causation.
In search of answers
To get closer to the truth, we need to dig a bit deeper, including cutting the data in some new ways. Here’s the context: In total, we asked about 10 questions related to reliability, but there are two or three key ones. Of 644 executives, IT staff, and critical facility managers who answered this question, almost one third (30.8%) of the respondents had experienced an IT downtime incident or “severe degradation of service” in the past year, compared to just over one quarter (26.9%) when we asked the same question a year earlier. That looks like an appreciable and significant rise.
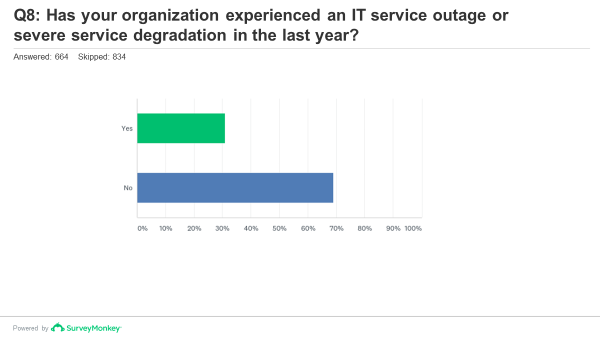
{kind=link}
{kind=link}
We also asked: Have you experienced an outage in the past three years? This did not have a direct corollary question in previous years, but even so, the level of outages/incidents was far higher than we might have expected (48.1% said yes). This certainly does not look like the industry is achieving the kind of 99.999% availability that is so widely claimed. But the discussion doesn’t stop there. Uptime Institute increasingly looks at outages as being complex and often multisite IT service outages—not just single-site facility events.
And we want to better understand what causes outages—what percentage can be attributed to power, or networks and IT, or even third-party services, so we slightly changed the wording. In 2018, we said “IT service outage or severe service degradation.” In 2017, we used the term “a business-impacting data center outage in your own data center or a service provider’s data center.” That change, unfortunately, is not ideal for comparison (although both definitions clearly cover a range of outages).
But a second issue is that the samples in both surveys include facility managers, IT management, and executives. And this raises the question, “Does a data center manager see the same number of outages as a senior IT manager or CIO?” A CIO is very likely to be responsible for any service that runs in a public cloud, a colocation data center, or a primary enterprise facility—and so will likely have a wider view of failures (including degradation).
We can provide a clue to this: Uptime did collect data on job roles and how they experienced failures for 2018. And yes, the 2018 data does suggest that CIOs see and report more failures. 38% of IT managers said their organization had experienced an outage in the past year (57% over three years). Managers of critical facilities reported a far lower number: 22% said they’d experienced an outage for a total of 38% over three years. In both cases, the outage (over two thirds) affected only a single site. However, IT management reported networking as being the most common issue whereas facilities managers reported that on-site power was the biggest cause of outages. For several reasons, business managers tend to see fewer outages.
So, does this mean that outages are going up or not? With a little trepidation, we went back and unpacked the sample from a year earlier. What we found was that the those identifying as managers of critical facilities saw more failures in 2017 (at 28% v 22% in 2018). But the percentage of managers of IT reporting failures increased to 38% in 2018, an increase of 5% from 2017.
Overall, the total percentage of survey respondents reporting failures rose, but the results suggest that those with wider IT roles see more failures, even allowing for some ambiguity and change in roles and definitions. This finding seems to be likely due to more IT and network failures. If we were to examine this finding further, we’d expect to learn that the increase in outages has little to do energy efficiency—although, as an aside, N+1 facilities report a higher failure rate than the more expensive, less energy-efficient 2N architectures.
All these findings support the Uptime Institute’s position that it now makes sense to look at reliability and failures holistically, with problems in IT and at service providers, being taken into account along with site-related issues. After all, the customer does not experience outages in silos or layers.
In our report on this survey, and a more detailed one on outages, we said that Uptime Institute data shows outages are still “common, costly, and preventable” and “may even be increasing.” Setting aside all the nuances, the message to anyone running a business based on data center and critical IT services is fairly simple: Pay attention to all the services and the whole stack—or pay the price.