
Business technology is under tremendous pressure and most organizations are ill-equipped to deal with the challenges and opportunities that are arising. Software as a service, big data, cloud, scale-out, artificial intelligence, containers, OpenStack and microservices are not just buzz-words, they are disrupting traditional business models. While these terms and technologies represent a new world of opportunity, they also bring complexity that most IT departments are ill-equipped to deal with. This has become known as the era of Big Software.
Monolith to micro-mix
To address the realities of Big Software, companies need to think differently. Traditional enterprise applications were monolithic in nature, procured from best of breed providers and installed on a relatively small number of large servers. Modern application architectures and capacity requirements force companies to now roll out many applications, components and integration points spread across potentially thousands of hosted physical and virtual machines on premise or in a public cloud. Organizations must have the right mix of products, services, and tools to match the requirements of the business yet many IT departments are undertaking these challenges with the approaches and tools developed over a decade ago.
Some IT directors have turned to public cloud providers like AWS (Amazon Web Services), Microsoft Azure, and GPC (Google Public Cloud) as a way to offset much of the capex (capital expenditure) of deploying hardware and software needed to bring new services online. They wanted to consume applications as services and offset most of the costs to opex (operational expenditure). Initially, public cloud delivered on the capex to opex promise (according to analysts including Moor Insights & Strategy) with cloud providers touting upwards of 45 percent in capital reductions in some cases, but organizations needing to deploy solutions at scale found themselves locked into a single cloud provider with fluctuating pricing models, unable to take advantage of the economies of scale that comes from committing to a platform. Forward thinking IT directors realized they must disaggregate their current data center environments to support scale-out private or hybrid cloud environments.
{kind=link}
{kind=link}
{kind=link}
The economics of OpenStack
OpenStack is a way for organizations to deploy open source cloud infrastructure on commodity hardware. Customers look at OpenStack as an opportunity to reduce the cost of application deployment whilst increasing the speed with which they can bring new application services online. The cost to deploy OpenStack is relatively low, the ongoing investment in maintenance, labor, and operations can be high as some OpenStack solutions are unable to automate basic tasks such as updating and upgrading their environment. The cost of staff experienced and able to operate OpenStack at scale is high.
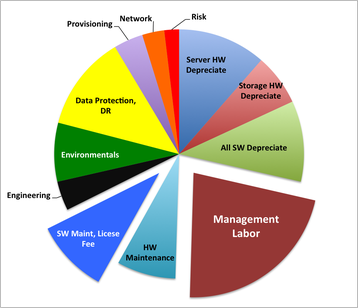
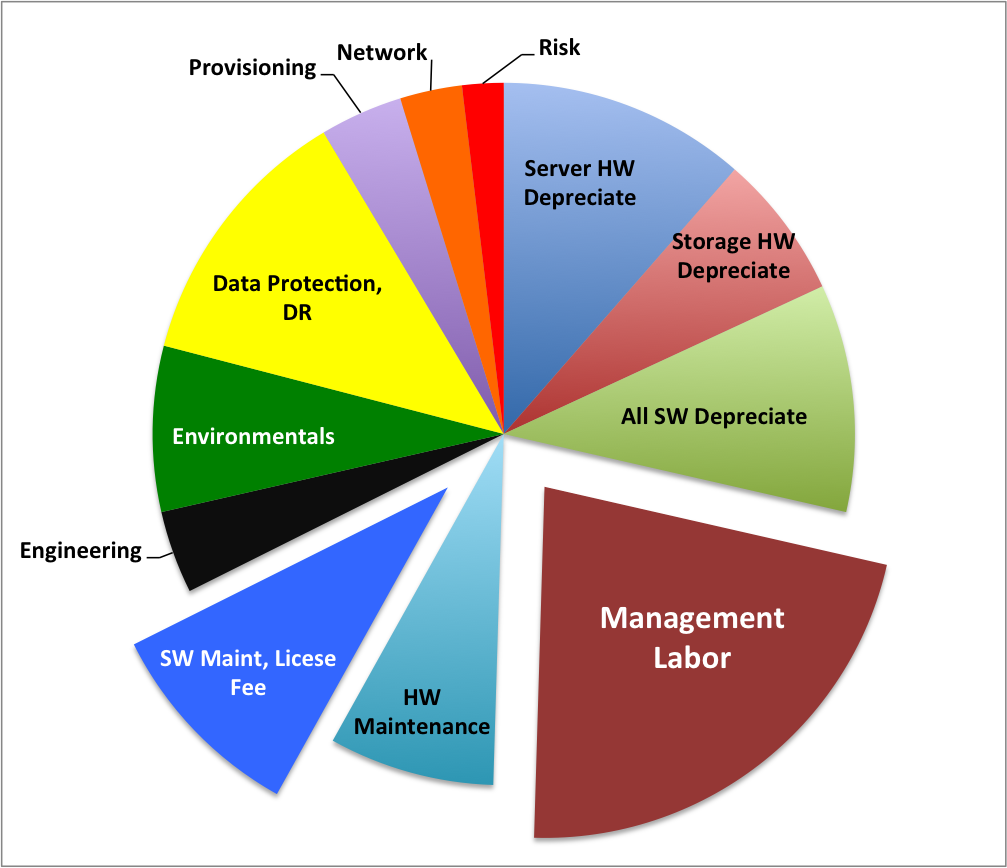
One of the main challenges with OpenStack is determining where the year-over-year operating costs and benefits of managing the solution reach parity, not just with public cloud, but with their software licensing and other critical infrastructure investments. Our experience working with many of the largest OpenStack deployments out there is that in a typical multi-year OpenStack deployment, labor can make up more than 40 percent of the overall costs, hardware maintenance and software license fees contribute around 20 percent, while hardware depreciation, networking, storage, and engineering combine to make-up the remainder.
Using virtual machines (normally VMware) for in-house IT has a high labour cost, according to research by has shown a high labor cost, according to David Merrill, chief economist at HDS . For OpenStack, the labour cost would be increased, with a decrease in software costs, Merrill observes.
Whilst the main advantage of moving to the public cloud is still the short-term reduction in the cost per headcount and the speed of application deployment that is unhindered by organisation inflexibility, the year-over-year public cloud expenses can be greater than using an automated on premises OpenStack implementation.
We need to automate deployment
Building a private cloud infrastructure with OpenStack is an example of the big software challenge. Significant complexity exists in the design, configuration, and deployment of all production ready OpenStack private cloud projects.
In a typical multi-year OpenStack deployment, labor can make up more than 40 percent of the overall costs
While the upfront costs are negligible, the true costs are in the ongoing operations; upgrading and patching of the deployment can be expensive. This issue can be addressed with new tools designed to model, deploy and operate big software. Canonical has such tools, including an OpenStack Autopilot which sets up a flexible reference cloud, while other components and operations are encapsulated so new services can be connected and integrated automatically with lower labour costs, and microservices can enable features such as IoT, big data and security.
OpenStack is not a destination, but a part of the journey to delivering scalable services faster than ever before. CIOs know they must have cloud as part of their overall adoption and that OpenStack is a key enabler for hybrid cloud adoption. IT organizations that take a traditional approach will continue to struggle with service and applications integration while working to keep their operational costs from rising too much. The good news is, tools are emerging to handle the big software era.
Mark Baker is OpenStack product manager at Canonical