
During the past decade, enterprises have begun using machine learning (ML) to collect and analyze large amounts of data to obtain a competitive advantage. Now some are looking to go even deeper – using a subset of machine learning techniques called deep learning (DL), they are seeking to delve into the more esoteric properties hidden in the data. The goal is to create predictive applications for such areas as fraud detection, demand forecasting, click prediction, and other data-intensive analyses.
The computer vision, speech recognition, natural language processing, and audio recognition applications being developed using DL techniques need large amounts of computational power to process large amounts of data. To get the insights enterprises are looking for with DL, the underlying IT infrastructure needs to be deployed and managed as enterprise-grade. New solutions are being developed that make it faster and easier for organizations to gain actionable insights from rich, complex data.
Machine learning for automating data-driven decisions
Machine learning involves developing algorithms that operate by building a model from example inputs to make data-driven predictions or decisions. Such leading technology firms as Google, Facebook, Amazon, Baidu, Yahoo, Tesla Motors, and Walmart Labs have been using these machine learning tools to improve analytics applications for image recognition, programmatic advertising, and product and content recommendations. [1]
There are three types of machine learning: supervised machine learning, unsupervised machine learning, and reinforcement learning.
With supervised machine learning, the program is “trained” on a predefined set of criteria. For example, one may feed the program information on prior home sales prices based on neighborhood, number of bedrooms, and total square footage, and then ask it to predict what the sales price would be for new sales. While a good real estate agent knows how to price houses based on area, neighborhood, and similar factors, programming a computer to do that using standard techniques would be extremely cumbersome. Another example would be showing the computer predefined sets of data (like a collection of images of cats and dogs), to train it to properly identify other similar images.
Unsupervised machine learning means the program is given a large amount of data and must find nonlinear relationships within the data provided. An example of this might be looking at real estate data and determining which factors lead to higher prices in certain parts of the city. One major manufacturer is using this type of unsupervised machine learning to predict future demand for a variety of parts. In this way parts would be available for installation before equipment has to be grounded. A human expert may know roughly what factors affect the demand for parts but machine learning provides the additional data needed to automate that decision.
Reinforcement learning is when a computer program interacts with a dynamic environment in which it must perform a certain task. Examples include interacting dynamically with social media to collect data on the public sentiment on an issue. The computer can get information from data and predict future contributions in real time.
These machine learning methods work only if the problem is solvable with the available data. For example, one cannot use machine learning techniques to estimate the price of an air fare based on whether the customer has a dog. If the data would not help a human expert solve the problem, it will not help the machine either.
Machine learning gives enterprises the capability to not only discover patterns and trends from increasingly large and diverse datasets but also enables them to automate analyses that have traditionally been done by humans, to learn from business-related interactions, and deliver evidence-based responses. It also provides confidence levels in the likely success of recommended actions. It gives enterprises the capability to deliver new differentiated or personalized products and services, as well as increasing the effectiveness and/or lowering the cost of existing products and services.
However, machine learning is inexact computing, because there is no deterministic way of modelling features. Features are typically modelled as neural networks and the parameters depend on the quality of the input dataset.
Take the examples shown in Figure 1, where the top row is obviously images of children. However, for a computer a bitmap containing images of a child on a bicycle, on the beach, or turned sideways are completely different datasets. One would have a very difficult time teaching a computer to distinguish among them.
In some cases, the difference between such images can be a matter of life or death. For example, the bottom row contains images of road signs. It would be unacceptable for a self-driving vehicle to fail to recognize a road sign simply because it is covered with snow. An average human driver can recognize it because of its octagonal shape, and a computer should be able to do that too.

Deep learning emulates the layers of the human brain
Deep learning, a subset of machine learning, is a dynamic system that emulates the human brain, especially how neurons interact in the brain, and how different layers of the brain work together. Unlike ML, in DL features are modelled as a deep neural network with several inner/hidden layers that capture subtle information about the data and assign a physical meaning. DL enables partitioning the digital image into segments that make it easier to analyze; this means that high level information can be extracted and encoded for computer use.
For example, to a human, faces have eyes. To a computer, faces have pixels that are light and dark, making up some type of abstraction of lines. Each layer of a deep learning model lets the computer identify another level of abstraction of the same object. Using the earlier animal analogies, deep learning will let users distinguish picture of cats lying on the ground from those jumping.
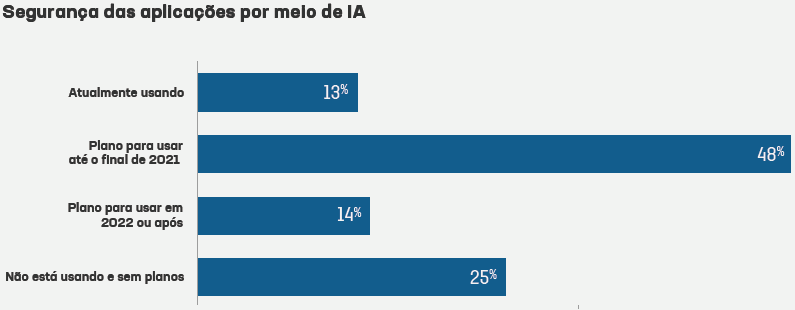
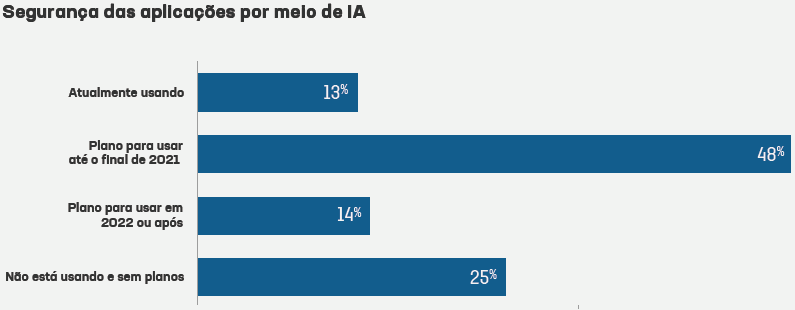
DL has made great progress in the past few years. For example, Figure 2 plots the accuracy of image recognition research conducted as part of ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which evaluates algorithms for object detection and image classification at large scale. The research is being done to enable researchers to compare progress in detection across a wider variety of objects and to measure the progress of computer vision for large scale image indexing for retrieval and annotation.
The blue on the figure shows traditional computer vision approaches available in 2010 and 2011, and the purple shows DL techniques available more recently. Red depicts the human accuracy rate, which is measured by asking individuals and groups of individuals to describe and classify images. Groups of people are allowed to deliberate over the shown image and reach a common answer. One immediately notices a very steady improvement over time. Note that computers using DL techniques became as efficient as humans at image recognition in 2015.
{kind=link}
{kind=link}
{kind=link}
Baidu Research’s Deep Speech project recently achieved human-level accuracy in speech recognition in both English and Mandarin using a single, deep recurrent neural network. This result demonstrates that DL is also useable outside the realm of computer vision.
Another interesting example is Google DeepMind, which used DL techniques in AlphaGo, a computer program developed to play the board game Go. AlphaGo’s algorithm find its moves based on knowledge previously “learned” by an artificial neural network by extensive training, both from human and computer play. In 2015, it became the first computer Go program to beat a professional human Go player without handicaps on a full-sized board. [2]
One final example of growing interest in DL techniques is the collaboration between DeepMind and Blizzard, which are developing StarCraft II. Using one of the world’s most popular computer games, the project is being developed as a research environment open to artificial intelligence and machine learning researchers around the world.
Machine learning poses formidable computational challenges
These examples of ML and DL techniques are impressive, but they pose a formidable computational task. Training for DL usually requires a few tens of quintillion FLoating-point Operation (FLOPs), which translates to a few weeks to a few months of time on a small cluster. Many, if not most, organizations cannot wait that amount of time to extract intelligence in a rapidly changing environment.
Deep learning software modules can take enterprises days to download and install if using open source repositories. Finding all of the dependencies for a given deep learning framework or library can take a lot of time. As these tools are still quite new, and many of the dependencies require that users ensure specific versions of specific libraries are available. Once found, users may need to perform time-consuming manual installation of all the libraries and dependencies. In some cases they must satisfy more than 60 dependencies. Many of these libraries are not installable from open source repositories of standard enterprise Linux distributions, which means users need to seek them out and install them manually, ensuring they are using versions that work together.
Users obtain no benefit from new hardware that has excellent nominal performance characteristics but lacks optimized libraries, because it can take months or years to create these libraries. In particular, DL requires efficient C interfaces to BLAS, FFTs, convolutions, malloc, and memcopy. NVIDIA has provided these required interfaces with cuBLAS and cuFFT, but such optimized libraries are missing from other dense hardware platforms. Typically it takes a couple of years to optimize these libraries on new architectures.
For those looking for an overview of available machine learning packages, A Plethora of Tools for Machine Learning, by Knowm Inc., provides a detailed comparison of more than 40 machine learning packages and libraries. [3]
Building a framework for deep learning
New tools and frameworks are emerging to make deep learning easier and organizations must select the right combination of software, hardware, network, tools, and libraries to develop and run applications efficiently.
The first order of business is to streamline the deployment, management, operation, and scaling of deep learning environments. Enterprises must start by enabling analysts and developers. Deep learning tools do not work in isolation. To be effective, organizations need to make the right collection of tools and supporting hardware and software frameworks available to their developers and analysts without turning them into IT administrators.
Although artificial intelligence and machine learning have been with us for decades, deep learning is still new, and constantly changing. Organizations need the flexibility to adopt new tools and practices as they emerge in order to respond to market needs in an agile manner.
A modern deep learning environment
To respond to these needs, Bright Computing developed its Bright for Deep Learning solution, available on Bright Cluster Manager Version 7.3. The new approach offers a choice of machine learning frameworks to simplify deep learning projects, including Caffe, Torch, TensorFlow, and Theano, and CNTK. It includes several of the most popular machine learning libraries to help access datasets, including MLPython, NVIDIA CUDA Deep Neural Network library (cuDNN), Deep Learning GPU Training System (DIGITS), and CaffeOnSpark, the open sourced solution for distributed deep learning on big data clusters.
Processing large amounts of data for DL requires large amounts of computational power. As new tools designed specifically for DL become available, developers are using them to build their applications on advanced high-performance (HPC) clusters that take advantage of accelerators such as NVIDIA GPUs.
GPUs make the calculation-intense procedures needed in machine learning perform much faster than CPU-only solutions. The Bright for Deep Learning solution offers GPU-accelerated versions of common ML libraries to make it easier to deploy and manage the hardware and the related software, APIs, and machine learning libraries. This means researchers and developers can focus on their work – instead of on managing the tools.
It also means that users do not have to worry about finding, configuring, and deploying all of the dependent pieces needed to run those deep learning libraries and frameworks. Included are more than 400MB of Python modules that support the machine learning packages, plus the NVIDIA hardware drivers, CUDA (parallel computing platform API) drivers, CUB (CUDA building blocks), and NCCL (library of standard collective communication routines). More will be added in the future, for example, CNTK, Bidmach, Keras, MXNet and others.
If users need more capacity, they can use the DL features to extend GPU-enabled instances into the cloud using Bright’s cloud bursting capability. They can also easily containerize deep learning applications, or run them in a private OpenStack cloud. Users can even take advantage of the performance provided by modern clusters by running a deep learning application using CaffeOnSpark.
Enterprises combining state of the art HPC clusters with deep learning
A variety of enterprises have been using the solution to combine state of the art HPC clusters with deep learning. For example, Stanford University is working on computer vision, natural language processing, and credit card fraud detection research. George Mason University is conducting an analysis of scientific simulation data.
Illumina, which develops sequencing and array technologies for life science research, translational and consumer genomics, and molecular diagnostics, is conducting research on gene prediction to identify the parts of the genome that encode certain functions. Samsung is working on using the Caffe DL network for work on computer vision for healthcare applications. RICOH is investigating DL methods for image recognition, and NYU Medical Center is testing DL tasks on HPC clusters.
Deep learning is very well aligned with traditional HPC workloads like those for big, dense linear algebra problems. However, there is currently a huge gap between the fastest DL cluster and the fastest supercomputer available today. While there are still many challenges, there is a significant opportunity to push the performance of DL further and to enable the usage of even larger datasets.
Panos Labropoulos is senior support engineer at Bright Computing, Inc.