
Over the past couple of years, software defined networking (SDN) has emerged as a strong alternative for IT operations in the areas of WAN, data center and overlay solutions. The primary benefit realized, besides open networking, is the ability to accelerate service deployments. SDN solutions using OpenFlow tackle complex problems including dynamic provisioning, interconnection and fault management. While the functionality of SDN evolved and matured, the scale of SDNs based on OpenFlow was still tied to ternary content-addressable memory (TCAM). OpenFlow by design was implemented in the TCAM.
The problem is that earlier switch ASICs like Broadcom’s Trident+ had relatively small TCAMs, and early versions of OpenFlow (1.0-1.2) could only use TCAM for memory. This limited OpenFlow scalability to 1000-2000 flows. But today, switch ASIC manufacturers are building larger TCAMs and OpenFlow developers have come up with ways to access other memory resources to support more flows in today’s switch ASICs.
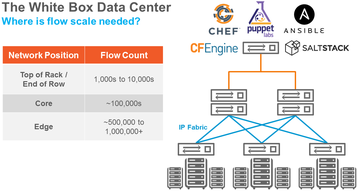
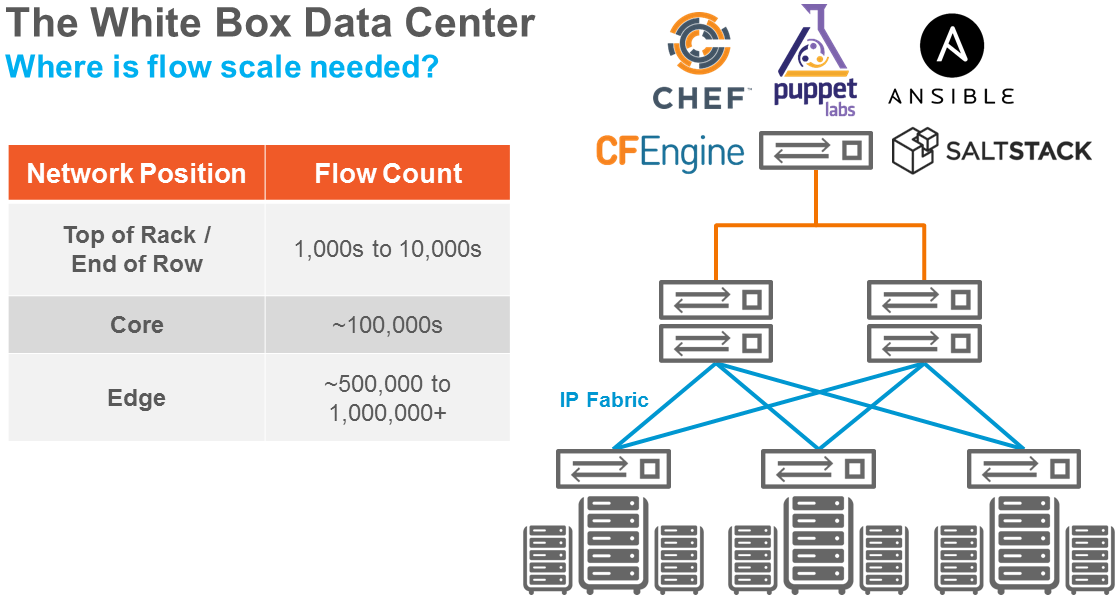
Flow requirements
Typical data center network infrastructure consists of top-of-rack switches, core switches, and edge switches. Each of these hierarchies needs a different level of flow scalability (Figure 1).
Given the requirements shown in Figure 1, it’s easy to see the early reluctance to implement OpenFlow. Essentially, these limits were mandated by OpenFlow’s reliance on TCAM memory devices for storage of flow routing information.
About TCAMs
TCAMs are special memory devices that enable most of today’s intelligent networks. They enable match on a masked bit value rather than a binary match. This greatly enhances the usability of TCAM for network applications. Primarily,
TCAMs were responsible for the development of the SDN concept. The possibilities in creating a policy-based forwarding model with a wild-card match introduced a multitude of network applications that enabled custom, exception-based, sub-optimal, time-of-day, cost-optimized and other such forwarding models. OpenFlow started with using TCAMs in network devices as the primary resource to enable some unique functionality. OpenFlow greatly augmented traditional routing protocols to accommodate core business requirements.
The trouble with TCAMs
However, as the benefits of OpenFlow expanded in scope and capabilities (including control plane disaggregation and open networking), the scaling of OpenFlow tables became a major concern and a limiting factor. TCAMs are power hungry, expensive memory devices that bloat the cost of solutions. While embedded TCAMs offer a good price point at lower power consumption, they still cannot scale well and restrict the search to a priority model. This is particularly important since for IP lookups, longest-prefix match and related tree-based algorithms are more common and effective at scale. DRAMs and SRAMs have long been used for these applications since they provide cost and power benefits over TCAM.
For years, legacy network equipment makers have derided OpenFlow by saying it doesn’t scale to handle major networking tasks
While OpenFlow started out by exploiting the TCAM capabilities, it was not optimized for some simple forwarding applications such as a typical routing or a Layer-2 pipeline. In order to achieve flow scale it is imperative to use available memory resources on the ASIC to distribute flows to the appropriate resources to optimize the memory usage. Earlier versions of OpenFlow from 1.0 through 1.2 relied on single-table implementations, i.e., using TCAMs only for flows. The optimization pretty much meant that a software layer would interpret the flows provisioned and would compress them into single or multiple flow entries in hardware.
Table type patterns
Table Type Patterns (TTP) address TCAM limitations by enabling OpenFlow to access other ASIC tables such as the VLAN, MAC, and IP along with TCAM tables. As the network operating system (NOS) opens up the different tables in the ASIC, an OpenFlow application is able to control the population of these tables directly in a normalized way. What this means is that the TTP is persistent across ASIC architectures. As a result, the SDN application can scale across ASIC architectures without any modification. For example, a fixed pipeline for IP routing, policy routing or an MPLS flow could be made consistent across any ASIC implementation.
OpenFlow 1.3 introduced the concept of multi-tables and methods to access and populate other tables including VLAN, MAC, IP, and MPLS. This brought in the ability to push flows to the appropriate hardware tables depending on the headers used for defining the forwarding path. OpenFlow 1.4 improves the management of flows in multiple tables with sophisticated methods such as bundle messages, eviction and vacancy events, and synchronized tables among others.
So while the NOS normalizes access to the ASIC hardware tables, organizations are able to build their SDN applications that persist across vendors and accelerate adoption of open networking and SDN deployments. With TTP, network engineers and operators can now implement SDN at greater scale – in some cases, up to two million flows (a 1,000x increase from previous methodologies) – while still using standard, white box hardware.
{kind=link}
{kind=link}
{kind=link}
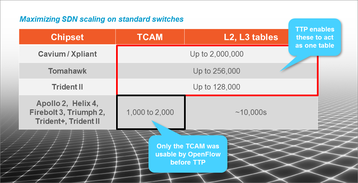
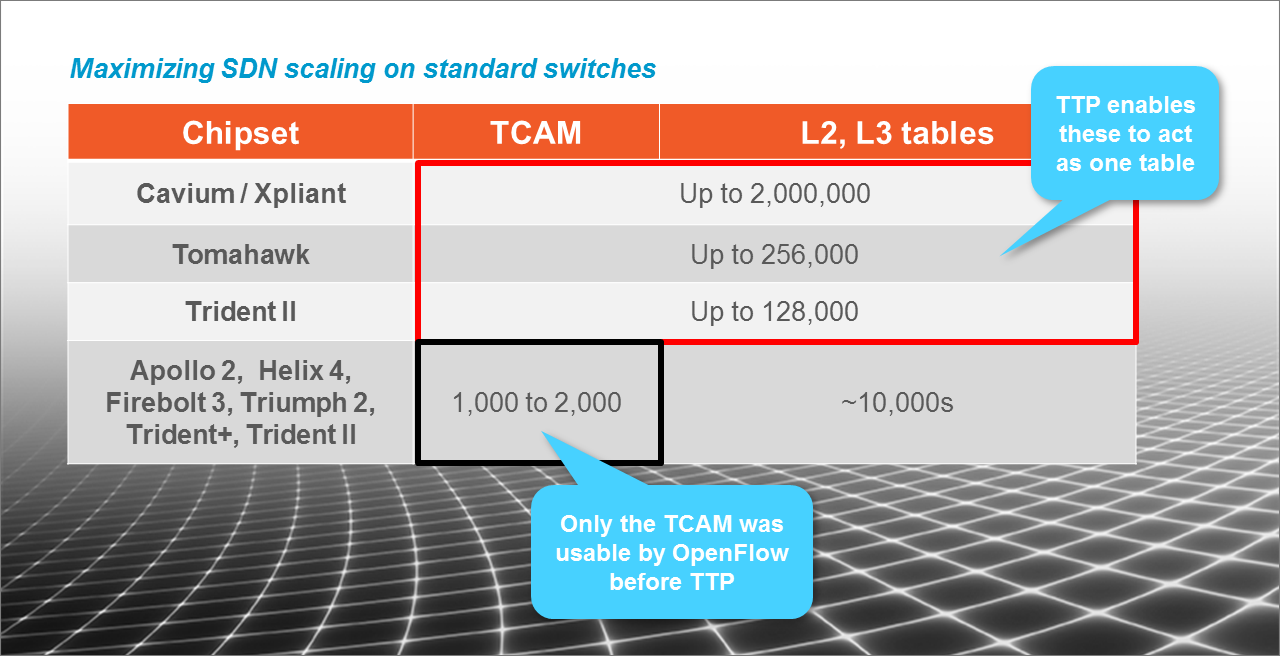
New ASICs deliver more scale
On the development curve, software always leads hardware because software can be developed more quickly and with a smaller investment. But ASIC vendors are catching up to OpenFlow 1.4 with new products like Broadcom’s Tomahawk and Cavium’s XPliant switch ASICs. These support 256,000 and 2,000,000 flows, respectively, (Figure 2.)
Applications for scalable OpenFlow
So how do network operators leverage OpenFlow’s scalability? Here are a couple of examples. For ISPs, for example, automation and self-service portals are nirvana for the reduction in OpEx alone. If a customer wants to increase bandwidth from 10Mbps to 100Gbps, but only wants to do it from 8:00am – 5:00pm, and also wants to apply a firewall filter and a QoS policy, this would be hard to do quickly with standard network provisioning and protocols.
ISPs are therefore looking at OpenFlow to achieve this level of automation and granular control. The network uses Layer-2 and Layer-3 protocols as the baseline transport, and OpenFlow rules are used to define the exception based forwarding that end users want.
When considering the requirements of multi-tenancy, dynamic VLANs, virtualized services, and scale, it’s easy to see why scaling the number of OpenFlow rules would be important in this scenario.
Handling elephant and mice flows in the data center is another well-known problem for large enterprise or service provider data centers. Data center networks have standardized on some variant of spine-and-leaf architectures, which makes perfect sense when it comes to east-west traffic and the ability to quickly add scale.
However, problems can still arise when it comes to handling different flows of different sizes and how packets get queued when bandwidth is at a premium. The beauty of using OpenFlow in this instance is that it does not disrupt what is already working with the spine-and-leaf architecture. Whether it’s MLAG, BGP, or any other standard protocol, network operators have been able to strategically stitch in OpenFlow rules to handle these elephant flows as special cases. And considering the number of virtual machines and workloads in data center racks today, it’s easy to see why the ability to increase the number of OpenFlow rules is important.
For years, legacy network equipment makers have derided OpenFlow by saying it doesn’t scale to handle major networking tasks. But with advances in software and switch ASICs, the open networking ecosystem is enabling network operators to scale OpenFlow deployments to any size needed, and to move forward with new, tailored services.
Sudhir Modali leads the SDN strategy at Pica8