
Data center operators today are challenged to deliver enough capacity for their organization’s growing needs while simultaneously managing capital and operational costs. The demand for compute power and data storage capacity is growing by as much as 30%-40% per year in some segments as data centers scale up to meet service level agreements (SLAs) for new applications such as Big Data, Machine Learning, and real-time IoT analytics.
However, even virtualized environments rarely exceed 40% average utilization and non-virtualized data centers run at around 20-30% utilization, which leads to higher than necessary capital and operational spending on unused capacity. So we’re seeing a paradox of low utilization even while facing insatiable demand. What technologies and best practices can help us solve this paradox?
Equipment utilization is one of the challenges that hyperscale cloud service providers (CSPs) have addressed quite successfully. If they were not operating at very high utilization, their business models—based on the ability to serve massive, dynamically changing workloads cost effectively—would not succeed. For example, even while growing at record rates, Google and Facebook have achieved a 4X improvement in CPU utilization versus traditional data centers (2X for virtual workloads), and a 10X improvement when it comes to the number of servers that can be managed by an administrator.
They have made some general aspects of their technology public: a combination of purpose-built hardware with built-in flexibility, interfaces to configure and manage this hardware completely under software control, and extensive automation based on custom software. At a leading hyperscale data center, for example, a single administrator has the ability to provision and manage thousands of servers, vs. hundreds for the typical data center. Hyperscale CSPs are also deploying large all-flash arrays to remove hard disk storage bottlenecks, and they typically upgrade their CPUs every three years, faster than the industry average five year cycle. However, many of the details of how the Mega-CSPs optimize and manage their infrastructures are proprietary, secret, and would require huge investments to duplicate. Data center operators who don’t have the massive scale of a Google or Facebook want to achieve some of the same efficiencies—but how?
An industry blueprint
Intel has been aware of these challenges and working on a solution for some time. In addition to implementing new capabilities for hyperscale in silicon, Intel is also defining a new hyperscale data center architecture, called Intel Rack Scale Design (RSD) [formerly Rack Scale Architecture], which implements a concept known as composable disaggregated infrastructure (CDI).

To gain the added flexibility needed to improve utilization and agility, today’s servers with their fixed ratios of compute and storage resources must be “disaggregated”, i.e., broken down into their constituent components (e.g., compute modules, non-volatile memory, accelerators, storage, etc.) and managed as “pools” (groups) of available resources. When disaggregated components are provided with scalable management APIs and a flexible interconnect scheme, they can then be managed as pools of resources, which can be configured, or “composed,” on demand into logical systems optimized for specific workloads and applications.
When a composed system is no longer needed, its resources can be released back to the resource pools for use by another workload. The combination of disaggregation and composability allows data center operators to reduce overprovisioning and achieve higher efficiencies, like the Mega-CSPs. Because RSD is a software defined infrastructure, it also supports the kind of automation that the Mega-CSPs employ. For example, RSD can work with OpenStack, Canonical MaaS, and other cloud and virtualization environments.
Intel RSD defines two key aspects of a composable disaggregated infrastructure. The first is a design specification that defines the hardware and software capabilities needed at the module and rack levels to enable composability and scalable software control of the infrastructure. The second is a common set of open APIs that Intel, as a member of the DMTF, has proposed as extensions to the RESTful Redfish management framework. These APIs expose composability hooks to higher level orchestration software that can be sourced from multiple open source or commercial suppliers. By providing these open building blocks, Intel RSD helps accelerate adoption of CDI and provides a basis for innovation free from vendor lock-in by ensuring stability and broad interoperability.
In an RSD-based data center an operator using an orchestration console like OpenStack could configure and specify which of the infrastructure’s components — including CPU/DRAM, NVM, HDD, FPGA, and other resources — will run each workload based on the workload’s requirements and the components’ capabilities. In the future, such on-the-fly composition and provisioning could be done automatically via an advanced analytics-based data center optimization solution (itself an opportunity for market-driven innovation). Such an approach would adapt to the ever-changing types and mix of workloads that data center operators are challenged to support.
And since components are no longer dedicated to specific servers (due to disaggregation), adding, removing, and replacing components can be done much more incrementally, cost effectively, and flexibly. You can independently upgrade CPU/DRAM, add accelerators, or expand SDD and HDD storage, while retaining components not ready for end-of-life. Savings in storage, power supplies, racks, chassis, fans, battery packs and other components can reduce refresh equipment costs by 40% or more. Also, upgrading disaggregated components is less complex than replacing and re-provisioning an entire server. In its own data centers, Intel has saved as much as 77% in technician time during refresh cycles.
Inside Rack Scale Design
A composable disaggregated infrastructure allows users to populate racks any way they like, buying what they need, when they need it. Compute modules, non-volatile memory modules, hard disk or solid state drive (SSD) storage modules, FPGA modules, and networking modules can be installed individually—rather than as part of a pre-configured “system”—whether packaged as blades, sleds, chassis, drawers, or in larger physical configurations. In RSD, implementing composable disaggregated infrastructure is enabled by software components accessed via APIs defined within the Redfish RESTful framework. These software components are connected physically by an out-of-band management network (typically 1G Ethernet) separate from the high-bandwidth rack data fabric (e.g., 100Gb Ethernet, Infiniband or an optical interconnect) that provides data links between resource modules.
Once a rack is populated, a system can be immediately composed from the resources available in the rack, or in multiple racks. For example, to meet the requirements for a specific application a user may want to compose a system with a 2-socket Intel Xeon compute module, a 500Gb Intel Optane module, an Intel FPGA module and a 4 TB HDD storage module. Once composed, the system can be provisioned with a bare metal stack (operating system, middleware, and application code), a virtual machine environment such as KVM or VMware, or a container environment like Docker.
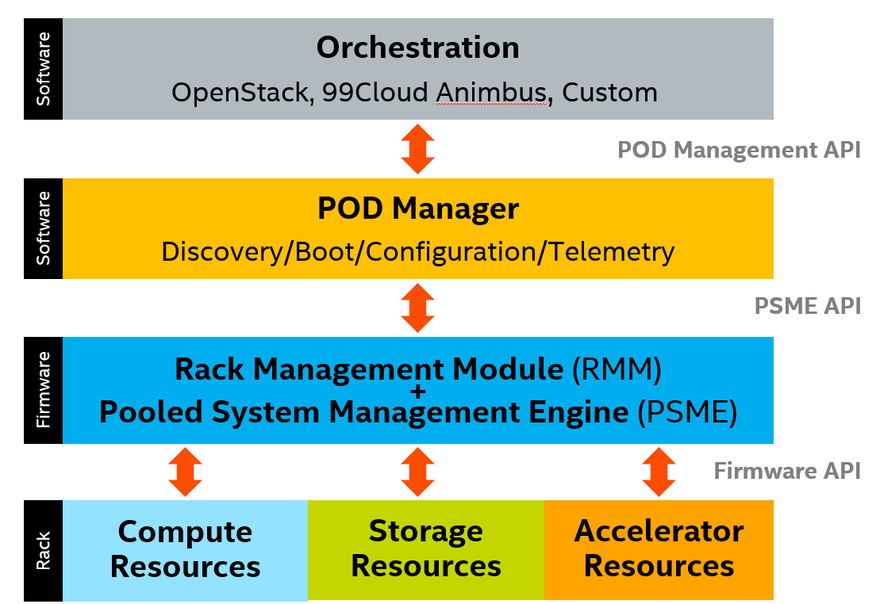
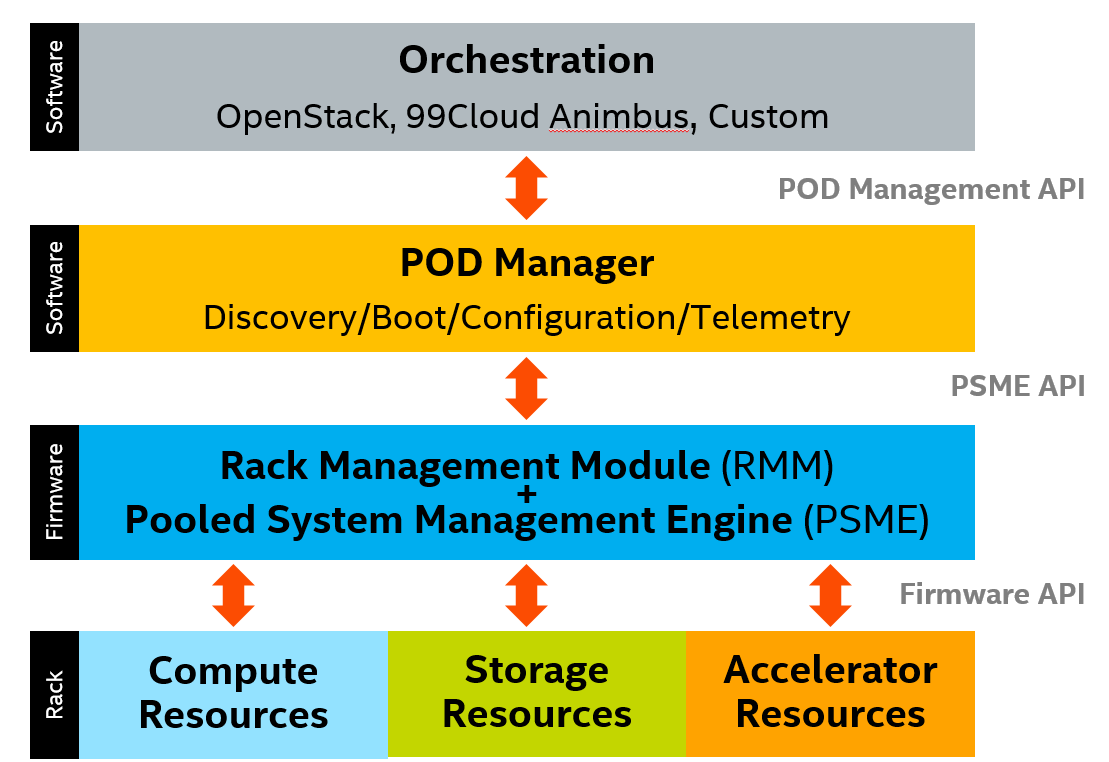
All this happens under software control using orchestration software such as OpenStack or a custom-built solution. This orchestration layer in turn communicates via the management network to three software structures — PSME, RMM, and PODM — that correspond, respectively, to three tiers of composable hardware — module, rack, and group-of-racks (pods) — as follows:
- Pooled System Management Engine (PSME). Each resource module in a rack has a PSME software component that provides basic control of the hardware, similar to IPMI, plus capabilities needed to support composability such as interconnect routing, storage volume creation, and so on. PSME integration with the physical hardware is implementation dependent, as it can run on each blade, each chassis, each drawer, or as one component for the entire rack, as long as the implementation provides PSME functionality for each contained resource and exposes the specified APIs to higher tiers. PSME.
- Rack Management Module (RMM). Each rack has an RMM, which communicates with the PSME and the PODM (discussed next) and performs a variety of rack-oriented functions. Those include distributing security certificates to PSMEs, managing rack power and cooling, reporting environmental and health status, and designating and reporting the physical location of each asset within the rack.
- Pod Manager (PODM). The PODM discovers and records all resources within each rack in its pod and composes systems based on requests from the orchestration layer above. Depending on which available resources align most closely to the requested configuration, the PODM asks the PSMEs to perform the required operations (setting switch parameters, mapping IP addresses, creating names spaces and storage volumes, etc.) and returns information to the orchestration layer to enable provisioning and workload distribution to the composed system.
{kind=link}
{kind=link}
{kind=link}
To ensure continued innovation and marketplace differentiation, all other implementation details are left up to each individual supplier, including density, rack dimensions, chipsets, module packaging, cables and connectors, and orchestration software.
To help enable the ecosystem, Intel provides reference software and specifies the software development vehicles (hardware) used by Intel to develop and test reference code). It also provides conformance tests to promote interoperability. Reference code and conformance tests are both available at the Intel RSD GitHub: https://github.com/01org/intelRSD. Intel RSD specification documents are available on the Intel corporate website at intel.com/intelrsd:
- The Rack Scale Design Platform Hardware Guide covers general specifications and design guidelines for platform hardware and components.
- The Rack Scale Design Software documents cover the functionality and APIs for the various components of Intel RSD software.
Intel also has a team of consulting architects, hardware engineers and software engineers who work with industry partners to help interpret the specifications, share design guidelines and experiences, make suggestions on implementation tradeoffs and capture partner suggestions and learnings to help guide the future evolution of the Intel RSD architecture.
A win for data center operators
Intel is providing RSD to spark adoption of CDI and remove the barriers of existing data center architectures. Suppliers can start making RSD compatibility part of their value proposition, and users can choose among differentiated but compatible CDI products. Suppliers such as Ericsson (HDS 8000), Dell (DSS 9000), Supermicro (Supermicro RSD), Quanta (Rackgo X-RSD), Inspur (InCloudRack), Wywinn (ST300) have already made their choice and have chosen to follow the Intel RSD roadmap. That’s good news for data center owners desperately looking for a win in the race to hyperscale.
Eric Hooper is director of Cloud System Engineering at Intel