Google Cloud and Seagate are using AI to predict when data center hard disk drives (HDDs) will fail, so Google can plan maintenance work and minimize disruption by replacing drives ahead of time.
The team tested two different AI models to predict which hard drives would fail, and found that an automated machine learning (AutoML) model worked better than a custom system, giving 98 percent precision - while also enabling Google to find new rules which would allow engineering teams to spot failures before they happened.
For breaking data center news, opinions, and features subscribe to DCD's newsletter

It didn't predict Chia
The technique could be very timely, as the data center industry is currently being struck by a cryptocurrency mining scheme called Chia, which awards coins based on monopolizing storage space on HDDs and solid state drives (SDDs), and working those drives very hard, causing consumer grade ones to break prematurely. It also follows other efforts to use AI techniques to improve reliability of data center hardware, including a Microsoft study that watched 180,000 data center switches in Azure cloud facilities and found which vendor and software combinations were most likely to fail.
"In the past, when a disk was flagged for a problem, the main option was to repair the problem on site using software. But this procedure was expensive and time-consuming. It required draining the data from the drive, isolating the drive, running diagnostics, and then re-introducing it to traffic," explains a blog post by technical program manager Nitin Aggarwal and AI engineer Rostam Dinyari at Google.
When an HDD is flagged for repair now, the ML system uses SMART data and other logs to predict if it is likely to fail again.
Google worked with its main HDD supplier Seagate, to create a machine learning system that would predict which drives would suffer recurring failures - suffering three or more problems in 30 days. The project also had help from Accenture.
Google has millions of drives, and each one generates hundreds of parameters of meta-information about its activity, including hourly SMART (self-monitoring, analysis, and reporting technology) data, as well as host data including repair logs, online diagnostics and field accessible reliability metrics (FARM) logs, and manufacturing data about the drive.
All this amounts to terabytes (TB) of data. "It’s practically impossible to monitor all these devices based on human power alone," say Aggarwal and Dinyari. "To help solve this issue, we created a machine learning system to predict HDD health in our data centers."
How to handle a data flood
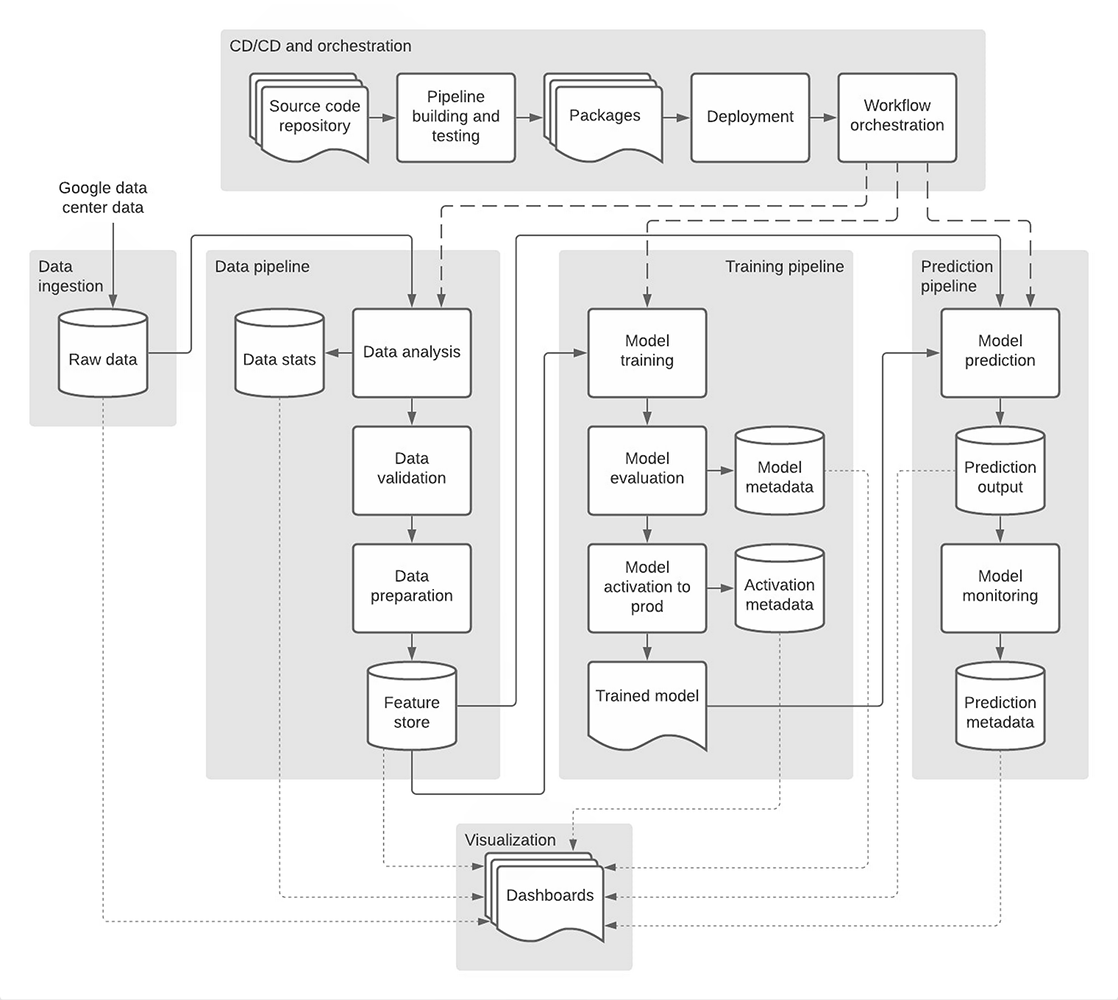
The AI system concentrated on the two most common Seagate drives in the Google facilities. The team had to build a data pipeline that could take the vast amount of logs and parameters from all the drives, process it quickly and monitor it continuously: "We needed to build a data pipeline that was both scalable and reliable for both batch and streaming data processes for a variety of different data sources," says the blog. "With so much raw data, we needed to extract the right features to ensure the accuracy and performance of our ML models."
The team used a bunch of Google's own AI tools, including Terraform, BigQuery, Dataflow, AI Platform Notebooks. AutoML Tables, and Custom Transformer-based Tensorflow models on the Cloud AI Platform.
AutoML Tables were a good shortcut, the project leaders say: "All we had to do was use our data pipeline to convert the raw data into AutoML input format."
The system uses BigQuery to make transformations, such as turning rows to columns, joining normalized tables, and defining labels, to it can get petabytes of data prepped and input into AutoML Tables for training the ML models.
The group tested two options. One, an AutoML Tables classifier, extracted key features such as error rates and concatenated them features such as drive model type. "We used a time-based split to create our training, validation, and testing subsets," say the project leaders.
For comparison, the group also we created a custom Transformer-based model from scratch using Tensorflow. It didn't need feature engineering; it worked with raw time series data, relating that to other data like drive type using a deep neural network (DNN). Outputs from both the model and the DNN were then concatenated.
Both models made forecasts of future failures, which could be compared with the actual drive repair logs after 30 days. The AutoML achieved a precision of 98 percent with a recall of 35 percent, while the Transformer-based model had a precision of 70-80 percent and a recall of 20-25 percent.
The system also identified the top reasons behind the recurring failures sp ground teams could take proactive actions to reduce failures in operations in future.
The team used Terraform to roll the systems out across the infrastructure and GitLab for source control versioning, with MLOps - a DevOps style approach - in which development and production versions are stored in two branches of the repository.
"Google's MLOps environment allowed us to create a seamless soup-to-nuts experience, from data ingestion all the way to easy to monitor executive dashboards." said Elias Glavinas, Seagate’s Director of quality data analytics tools & automation.
The results are so impressive, Seagate and Google are hoping to expand the project within Google: "When engineers have a larger window to identify failing disks, not only can they reduce costs but they can also prevent problems before they impact end users. We already have plans to expand the system to support all Seagate drives—and we can’t wait to see how this will benefit our OEMs and our customers! "



{kind=link}
{kind=link}