

The biggest barriers to reducing risk in the data center are:
- A lack of knowledge (both general and site-specific);
- A lack of processes to share this knowledge;
- A lack of site-specific experience;
- Unawareness; and
- Poor attitude, towards both people and learning
If a facility is complex, and there is a poor attitude towards learning, risk is invariably high.

Design complexity
Before considering design complexity, it is necessary to consider that for a resilient system – with no single points of failure (SPOFs) – a failure event must be, by definition, the result of two or more simultaneous events. These can be component failures, or incorrect intervention, for example switching without understanding how the system will react.
A 2N system could be considered the minimum requirement to achieve a SPOF-free installation. For simplicity, we will assume our 2N system comprises A and B electrical and mechanical systems. Fault tree analysis (FTA) will highlight combinations of events that result in failure; however, it is very difficult to model human error in an FTA. The data used to model human error will always be subjective and there are many variables.
If the systems in this 2N example are physically separated, then any action on one system should have no impact on the other. However, it is not uncommon for enhancements to be introduced that take the simple 2N system and add in further components such as disaster recovery links, and common storage vessels, which connect the two systems.
On large-scale designs, this becomes an automatic control system (SCADA, BMS) as opposed to simple mechanical interlocks. The basic principles of 2N have been compromised and the complexity of the system has risen exponentially. So too have the skills required by the operations team.
A desktop review of the design would still show that a 2N design had been achieved; however, the resulting complexity and challenges of operability undermine the fundamental requirement of a high-availability design.
Research has shown that often, the particular sequence of events that leads to a failure is unforeseen, and until it has occurred there was no knowledge that it would do so. In other words, these event sequences are unknown until they become known. It would not, therefore, form part of an FTA.
The Austrian physicist, Ludwig Von Boltzmann, developed an equation for entropy that has been applied to statistics, and in particular, to missing information. In this theory, a grid of boxes is set up – for example 4 x 2 or 5 x 4 – and a coin placed in one of the boxes. The theory allows the user to determine the number of questions needed to determine which box, on this defined grid, the coin is placed. If we substitute system components for the boxes, and unknown failure events for the coins, we can consider how system availability is compromised by complexity. It can be seen that with fewer unknown failure events, the number of ways in which a system can fail is reduced. Increasing our detailed knowledge of systems and discovering unknown events will therefore reduce the combinations in which the system can fail, thereby reducing risk.
The human element
Research shows that any system with a human interface will eventually fail because of vulnerabilities. A vulnerability is any possible weak points in a facility that could contribute to a failure. Vulnerabilities in a data cent34 can relate to either the facility infrastructure or the operation of the facility. The infrastructure relates to the equipment and systems, and in particular:
- The mechanical and electrical reliability; and
- The facility design, redundancy and topology
The operations relate to the human element and include human error at both individual and management levels. It relates to:
- The resilience of the operations team; and
- How well the team reacts to a vulnerability
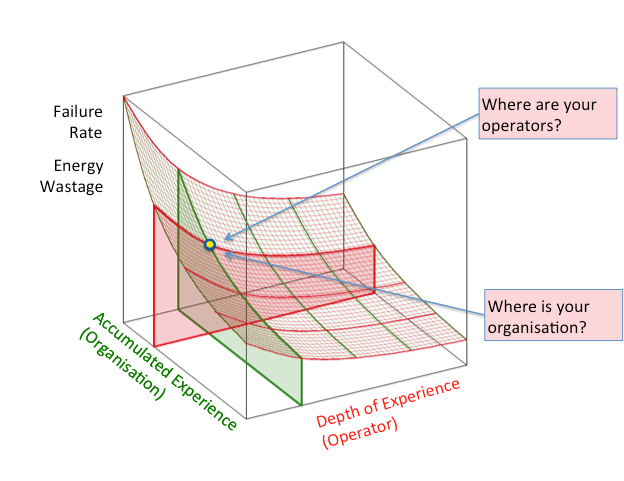
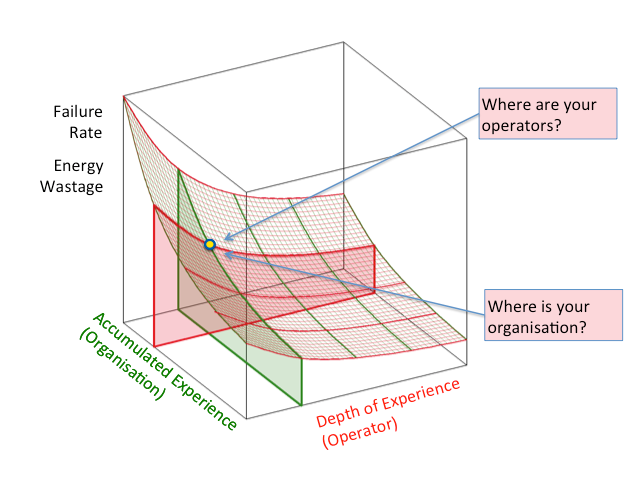
The more complex the system, the more vulnerable the ‘human element’ becomes, and the more training/learning that is required to operate the facility. Learning does not apply to individuals alone, but also to the organization. Organizational learning is characterized by maturity and processes (shown on the diagram below as accumulated experience), for example around structure and resources, maintenance, change management, document management, commissioning and operability and maintainability.
Individual learning is a function of knowledge, experience and attitude (shown on the diagram as depth of experience). An environment where both organizational and individual learning are developed helps reduce failure rate and equips operators with the know-how to reduce energy wastage more effectively.
{kind=link}
{kind=link}
{kind=link}
It’s important to understand that you can never get to zero failures as the relationship between failure and experience follows an exponential curve. Facilities with good procedures and experienced operators can still be vulnerable to complacency, and experience failures from a sequence of previously unknown events.
Conclusion
Data center risk can be reduced by providing a learning environment, in which organizational and individual knowledge can be improved. Whilst a mature operator has experience which can reduce the failure rate, an overly complex design, if implemented without adequate training, can still create failures.
Dr Beth Whitehead is an associate sustainability engineer at Operational Intelligence