
Benjamin Franklin said: ”In this world nothing can be said to be certain, except death and taxes”. But there is a third certain thing in life and that is the fact that IT will continue to advance and become more complex and hence need better management if it is not to run riot.
The question becomes “what do I manage and how?” In the service performance and capacity planning arena, this refers to the mass of data produced by operating systems which needs to be stored, accessed, analysed and used productively, not just for pretty graphs and elaborate tables.

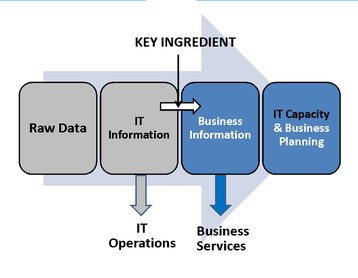
Raw data
This raw data by itself is fairly useless unless analyzed in some way to produce the key ingredient Information. The audience for this information is in two groups; IT people and business people. The IT faction wants summaries of the raw data for problem and planning purposes, the business people want information about their business services: online orders, web site performance and acceptability and so on.
This sounds a tall order, like making gold from lead but today there are alchemist products which can do the IT equivalent and produce business information from IT information, itself derived from IT raw data. The two issues in performance are:
- sizing the design of a system to provide a service
- capacity planning or ‘how will we perform in the future’?
Complexity
The IT world today is light years away from the classical world of a mainframe linking to non-intelligent terminals, where sizing was key since upgrades were prohibitively expensive. Sizing today is less of an issue because of cheaper hardware and modular building blocks for systems. Today’s environment is so complex (due to user driven requirements) that certain techniques have been introduced to make the complex easier to handle. These are commonly known as abstractions.
Abstractions are simple views of a complex IT situations which makes then easier to understand and use but do not really help IT operations and problem determination which operate below the abstraction line. Examples of abstraction are:
- virtualization and the cloud
- software defined entities; networks (SDN), data centers (SDDC) and storage (SDS)
Operations Issues
How then do operations manage systems and services if these concepts do not help them? Previously, IT had to analyze raw data manually, perhaps with the help of a software tool but in 2016, with hundreds of servers, clouds of various kinds this is a mountain of a task. This is where intelligent analytical and forecasting tools can make life easier and management of IT much more effective. However, even with such tools, there needs to be a methodology for their use.
Reporting on every IT entity is like bringing all 200 million US citizens to court to see who is guilty of any misdemeanors
Managing a very complex service environment by monitoring, analyzing and reporting on every IT entity that moves is counter-productive. The most effective way to achieve this is management by exception. This means concentrating on elements of the IT systems which approach or exceed established norms or baselines. An analogy is a legal one. It is useless to bring all 200+ million US citizens to court to see who is guilty of any misdemeanors; it is better to set laws and handle any transgressors - actual or potential - in the courts.
Problem summary
Today’s IT environment is too complex for man to handle alone, especially as the budgets for people are reducing and the task facing them mounting almost exponentially; which is a double whammy. Getting it wrong can be expensive since the attitude ‘with the cloud I can get all the power I need’ forgets the fact you have to pay for it !
The solution has to be tools and techniques which allow raw IT data to be analyzed to be predictive in terms of capacity and problem management and support both IT and the business, achieving what is often trotted out as the mantra ‘aligning IT with the business’ without any methods to support it.
The problem examined
So, we have posed the problem which is how do we deal with a complex environment with fewer people and ensure the service to the business meets the requirements of any service level agreement (SLA) between business and IT. Without assuming any particular SLA, it is nevertheless fair to assume that the following will be assumed if not specifically outlined in the SLA:
- adequate response times, particularly on web sites used by the public doing business online with a company.
- consistent response times which are key to productivity and customer satisfaction.
A dilemma
It is possible to have an average response time of, say, 2.5 seconds. This sounds better than an average of 2.7 seconds; but it’s not necessarily so. If the 2.5 sec, average response time corresponds to actual measured response times of 0.1 s., 6.5 s., 0.2 s., 11.5 s., 0.12 s., etc. then the end user is going to be extremely agitated and lose concentration. If, however, the 2.7 sec. time is made up of a cluster of numbers like 2.3, 2.6, 2.9, 2.7 .. and so on, the latter response time is universally preferred.
In order to keep good and consistent response, the computer resources need to keep that bit ahead of the business growth which in essence means capacity planning since driving those resources close to utilizations higher than a certain level means degradation in response times, response time consistency and throughput of jobs and transactions of all types. This is bad for business. Period.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
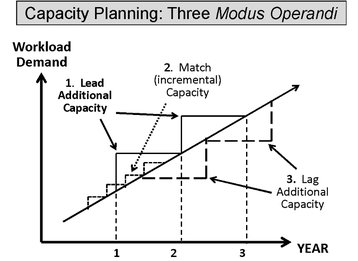
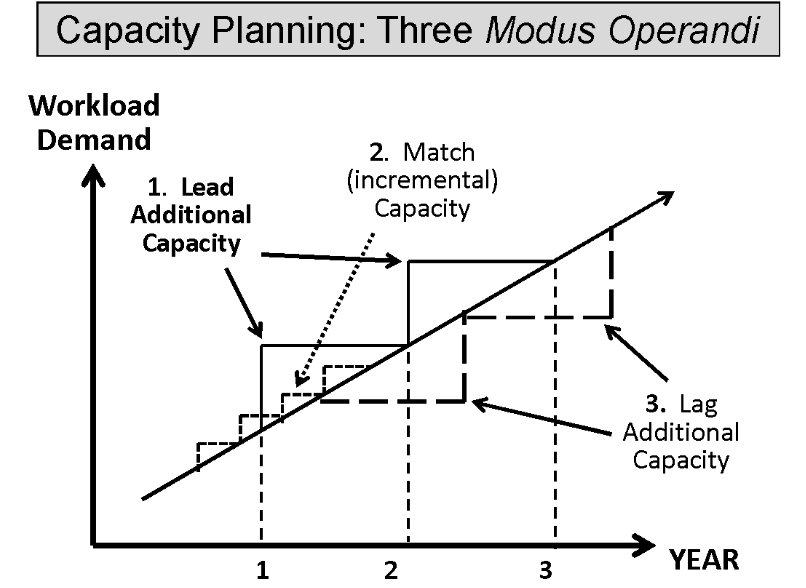
The options
The figure shows three ways of meeting increased demand. Method 2. is a risky choice, too close to call. Method 3 closes the door after the horse has bolted. Method 1. is the least risky but needs a good predictive capacity planning solution.
Capacity
Capacity planning and management are often thought of as old hat because resources are relatively very cheap compared with mainframe days. This is untrue and many analysts and customers are on board with this for some reasons already outlined - consistency of response time and other QoS (quality of service parameters. In addition, the complexity of virtualized environments and clouds can, and do, hide resource shortages for a particular application sharing resources with others. One suffers while another basks in an excess.
It is possible for one application to go short of resource despite the overall average looking adequate since another application may be getting more than its allocated share. It is impossible in such complex environments to keep the resource utilizations within the limits that don’t damage QoS otherwise service times will rise exponentially. This dictates knowing current and future resource demands (predictive capacity planning) to tie resources to the baseline for agreed service levels. This task is beyond manual activity, especially when irregular demand spikes occur in an already volatile environment.
A solution
In a cloud environment, the assumption that capacity is available immediately on demand to cater for spikes and other surges is not always true. In any case it costs money to increase resource usage and if there is an agreement with the cloud supplier (a form of SLA) there may be a penalty clause invoked. There may also be a delay in delivering that resource. The safe bet is to keep ahead of the resource consumption by rigorous capacity planning which, in a complex environment is not a manual task and is best handled by predictive capacity analytics.
Real time automated planning and predictive techniques which do not rely on human guesswork fulfils this need and keep resources assigned in line with growing requirements for them.
Terry Critchley is the author of High Availability IT Services, ISBN 9781498769198 - CAT# K29288