Amazon Web Services (AWS) is growing almost unbelievably quickly. On average, every single day in 2015, it deployed almost as much server capacity as it had in its entire infrastructure in 2005, according to the lead data center architect at AWS, James Hamilton.
Ten years ago, Amazon was already an $8.49 billion enterprise, so Hamilton could put it another way: Amazon’s public cloud is adding compute capacity equivalent to a Fortune 500 company every day. In a rare appearance on stage at Amazon’s re:invent conference in Las Vegas last week, the Amazon VP and distinguished engineer briefly lifted the veil of secrecy which normally surrounds the company’s global cloud infrastructure.

How big to build?
AWS has a global infrastructure of 14 regions, which is set to increase to 18 regions next year, but Hamilton made the additional claim that these regions have a more redundant structure of availability zones than the competition: “Our availability zones are real, and are separate buildings,” alleging that competitors sometimes lease two separate suites within the same data center and market them as redundant zones.
AWS has at least two availability zones (AZ) per AWS region, and can go up to as many as eight AZs, said Hamilton. Most AWS regions have three AZs, including new ones: “The regions we are building right now are three AZs, [supported with] two redundant transit centers, and are highly peered and connected facilities.”
Very large data centers have a substantially increased “blast radius” in the event of an outage.
The best size for an AWS data center is between 25MW and 32MW of power, with between 50,000 and 80,000 servers, said Hamilton. It’s easy to build data centers of 60MW to 120MW or larger, but the price economics improves much slower at this scale, he explained.
Very large data centers also have a downside: they have a substantially increased “blast radius” in the event of an outage. Hence, AWS favors building more data centers that are individually smaller for the increased redundancy and concurrent maintainability this offers, compared with building larger but fewer data centers.
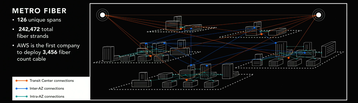
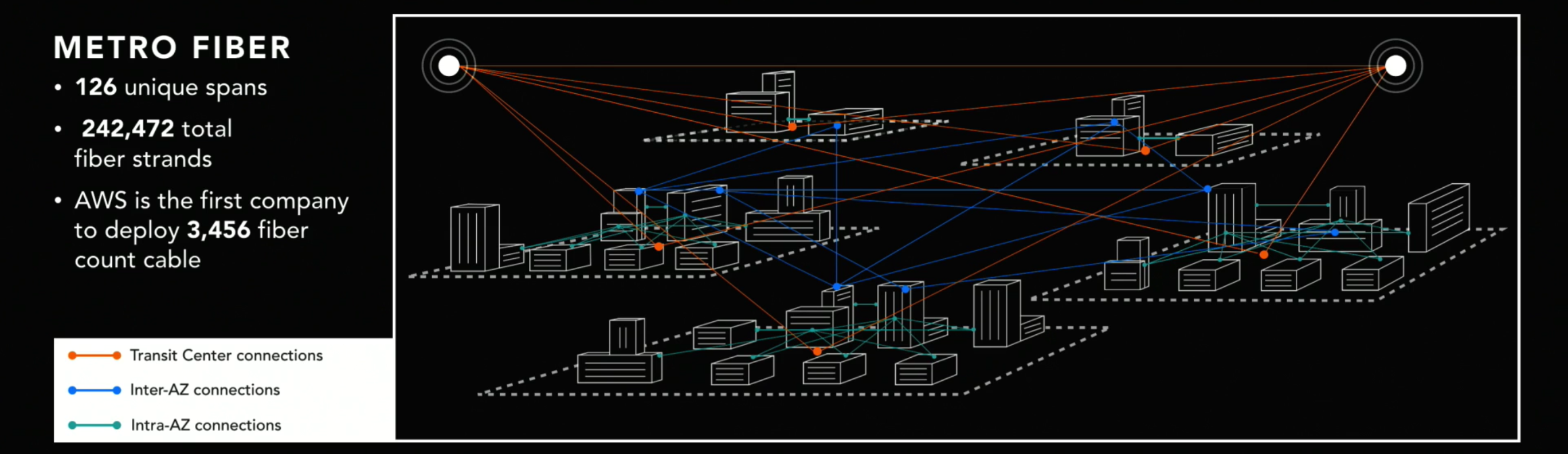
Redundant global fiber
The network linking these data centers also breaks records. AWS is the first organization in the world to deploy 3,456 fibers within its cables, said Hamilton.
All AWS facilities are wired into a metropolitan area network with redundant fiber optic links, he explained. In a region with five AZs, this adds up to 126 unique spans or up to a total of 242,472 fiber strands.
“Every one of the links is 100Gbps. Many, many 100Gbps links. It is really, really, really expensive”
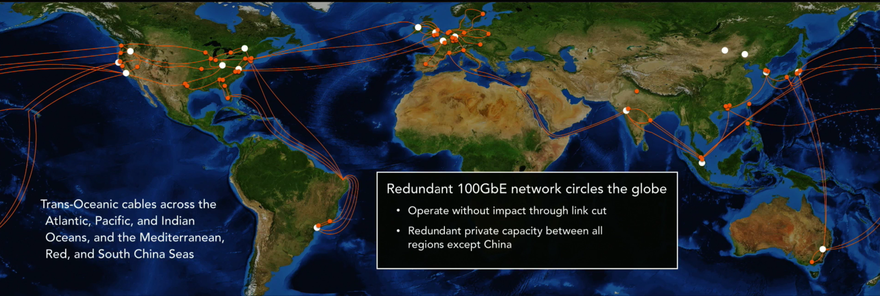
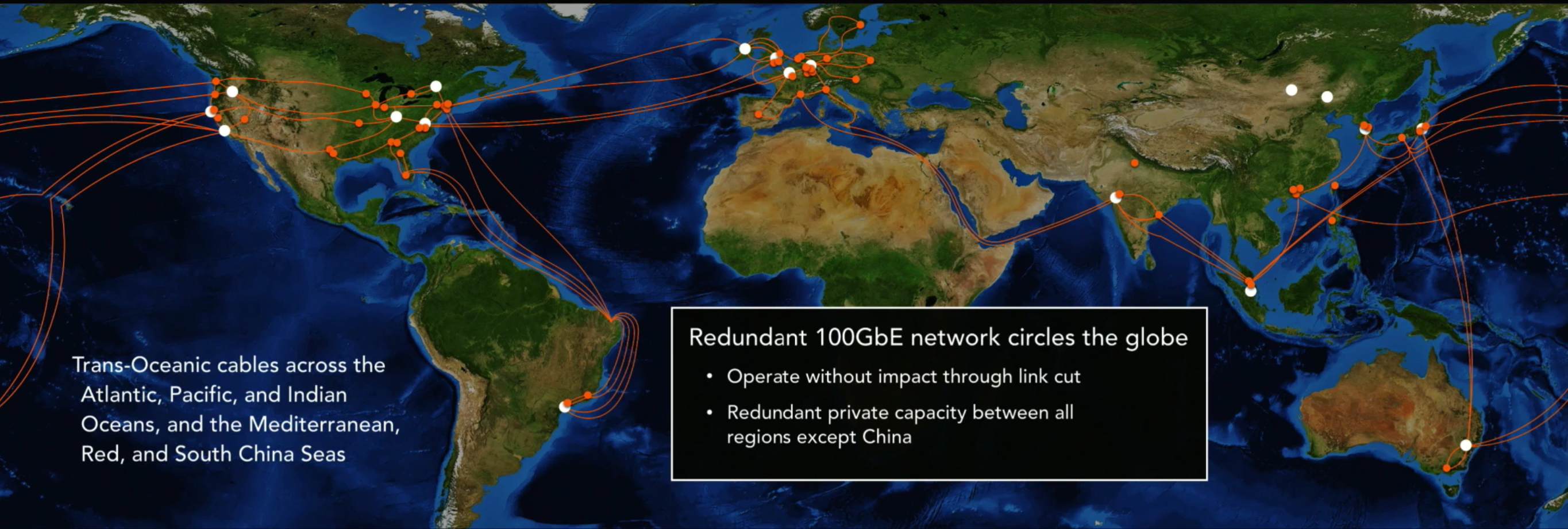
The regions are linked using private capacity which spans across three of the five world’s oceans (the Atlantic, Pacific, and Indian) as well as the Mediterranean, Red, and South China seas. The global network is based on 100GbE, and has redundant private capacity between all regions except China, soi it can survive a break in most of its links, according to Hamilton.
“Every one of the links is 100Gbps. Many, many 100Gbps links. It is really, really, really expensive,” he said. Some cables are leased, and some are laid by Amazon and its partners, but Hamilton didn’t go into details.
The newest project identified by Hamilton is probably the 24,000km Hawaiki cable, which links Australia, New Zealand, Hawaii, and Oregon with a design capacity of 42 Tbps. It is not known how much of the cable’s total capacity belongs to AWS because, like most such projects, it is being laid by a consortium.

Custom hardware
Within those data centers, a business on the scale of AWS can afford to specify its own hardware, and is also big enough to ignore the collective projects created by the Facebook-led Open Compute Project (OCP).
Amazon does not buy brand name routers for its data centers, as they are over-complex, and encumbered by a generic design, with features that AWS does not need, said Hamilton, repeating an argument made in 2015 by vice president of infrastructure Jerry Hunter. This translates into high cost, noted Hamilton, and it can take vendors up to 6 months to correct issues.
AWS decided to design its own routers to precise specifications, with the sole purpose of supporting the protocols it uses, and this worked out to its favor from the start, said Hamilton: “Our networking gear has one requirement. Keep it simple. It’s our phones that ring when it doesn’t work. When we headed down this path, we were making excuses that it won’t be as reliable at the beginning. [However,] it turned out way more reliable from day one.”.
A few years back, AWS made the decision to go with 25Gbps Ethernet (25GbE) at a time when the industry was moving towards 10GbE and 40GbE. Hamilton said 40GbE is essentially four lanes of 10GbE, while 25GbE future-proofed the AWS network, allowing a switch to 50GbE (2x 25GbE) which would deliver more bandwidth at lower complexity.
To drive this network, AWS now makes its own custom silicon for server network interface cards (NICs) thanks to its acquisition of Israel-based chipmaker Annapurna for $350m last year.
The new Amazon Annapurna ASIC supports 25GbE, and will enable even faster innovation, as it gives the cloud giant control over both software and hardware down to the silicon level, Hamilton said: “Every server we deploy has at least one of these in it.”
In its servers, AWS is not pushing for the highest density possible, favoring thermal and power efficiency in its custom servers, said Hamilton. This allows it to build data centers with a PUE of 1.12 and 1.15.
Sacrificing generators
Amazon also customized the utility switchgear for its data centers, rethinking the equipment’s software to make the uptime of the facility a higher priority than the lifetime of infrastructure equipment.
All commercial switchgear contains logic which blocks a power transfer to backup generators should a circuit fault be detected, because the on-site power generators could be damaged by certain circuit problems. With no easy way to tell where a fault is within the split-second window of a power event, AWS decided to modify the equipment to ignore the risk to power generators and initiate a power transfer anyway.
That could be the most striking illustration of Amazon’s obsession with preventing outages: to keep its sites up, it is prepared to run the risk of destroying generators costing three quarters of a million dollars.
{kind=link}
{kind=link}
{kind=link}
{kind=link}