
{kind=link}
Uno de los hallazgos del informe recientemente publicado por Uptime Institute "Análisis de interrupción anual 2020" es que las categorías más graves de interrupciones, aquellas que causan una interrupción significativa en los servicios, se están volviendo más severas y más costosas. Esto no es del todo sorprendente: tanto las personas como las empresas dependen cada vez más de TI, y cada vez es más difícil replicar o reemplazar un servicio de TI con un sistema manual.
Pero uno de los hallazgos plantea señales de alerta y preguntas: dejando de lado las que fueron parciales y/o que tuvieron un impacto mínimo, las interrupciones informadas públicamente en los últimos tres años parecen ser cada vez más largas. Y esto, a su vez, es probable que sea una de las razones por las cuales los costos y la gravedad de los cortes han aumentado.
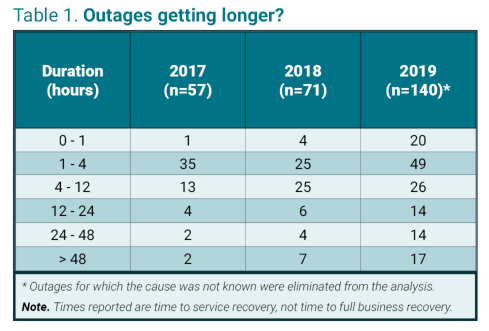
La tabla muestra el número de interrupciones informadas públicamente recopiladas por Uptime Institute en los años 2017-2019, excepto las que no tuvieron un impacto financiero o en el cliente o aquellas para las que no se conoció una causa. Las cifras muestran que los cortes están en aumento. Esto se debe a una serie de factores, incluida una mayor implementación de servicios de TI y mejores informes. Pero también muestran una inclinación en los datos hacia interrupciones más largas, especialmente aquellas que duraron más de 48 horas. (Esto es cierto a pesar de que una de las principales causas de interrupciones prolongadas, el ransomware, fue excluida de esta muestra).
La tendencia a interrupciones más prolongadas no es dramática, pero es real y preocupante, porque una interrupción de 48 horas puede ser letal para muchas organizaciones.
Pero, ¿Por que esta sucediendo? Es muy probable que la complejidad y la interdependencia de los sistemas de TI y una mayor dependencia del software y los datos sean la principales razones. Por ejemplo, la investigación del Uptime’s Institute muestra que menos interrupciones importantes son causadas por fallas de energía en el centro de datos y más por la configuración de los sistemas de TI ahora que en el pasado. Si bien la resolución de problemas de ingeniería de la instalación puede no ser fácil, generalmente es un asunto relativamente predecible: las fallas a menudo son binarias, y muy a menudo se han perforado procesos de recuperación en los operadores y se tienen a mano piezas de repuesto. Sin embargo, el software, la integridad de los datos y los procesos empresariales interorganizacionales dañados / interrumpidos pueden ser problemas mucho más difíciles de resolver o, a veces, incluso de diagnosticar, y estos tipos de fallas se están volviendo mucho más comunes (y sí, a veces se desencadenan por un fallo de alimentación). Además, debido a que las fallas pueden ser parciales, los archivos pueden no estar sincronizados o incluso estar dañados.
Hay lecciones que sacar de todo esto. Lo más importante es que los regímenes de resiliencia en los que ha vivido el personal de las instalaciones durante tres décadas o más deben extenderse e integrarse en TI y DevOps y deben ser totalmente respaldados e invertidos por la administración. Otra es que, si bien la recuperación ante desastres puede estar desapareciendo lentamente como un tipo de servicio de respaldo comercial, los principios de vigilancia, recuperación y recuperación de fallas, especialmente cuando están bajo estrés, son más importantes que nunca.
Por Andy Lawrence, miembro fundador y Director Ejecutivo de Investigación en Uptime Institute