Bjumper, compañía de ámbito internacional especializada en proyectos de gestión y operación en Data center, basados en propuestas unificadoras de procesos, personas y tecnologías existentes.
Se encargan de acompañar a sus clientes en la evolución del sistema de gestión desde la definición del marco operacional hasta la integración completa de los procesos y la tecnología, empleando en la tarea el software DCiM de iTRACS.
El objetivo de la ponencia es explicar la estandarización del modelo de gestión del Data center, basado en la norma EN50600, y en las mejores prácticas acumuladas desde los años de experiencia de Bjumper en la implantación de proyectos de gestión y operación del Data center basados en DCiM.
Comenzó Vicente la ponencia aclarando que no se trata sólo de emplear un DCiM como herramienta en la gestión de un Data center, sino que además se pretende emplearla según la norma del sector, la UNE-EN50600; y la herramienta DCiM que nos presenta el ponente, es capaz de alinear la necesidad operativa con la norma establecida y las buenas prácticas.
Es decir, no sólo se trata de un software DCiM que ayuda a los operadores a una gestión de sus actividades de manera más eficaz, sino de una evolución de éste que se conoce como DCSO (Data center Service Optimization) orientado al negocio (puede el lector encontrar información relacionada con estos conceptos en el dossier, elaborado por el mismo autor de este artículo, en el enlace http://bjumper.com/2016/07/19/dcd-madrid-2016-desde-los-ojos-de-un-espectador-de-cine, concretamente en la ponencia titulada “DATA CENTER SERVICE MANAGEMENT.
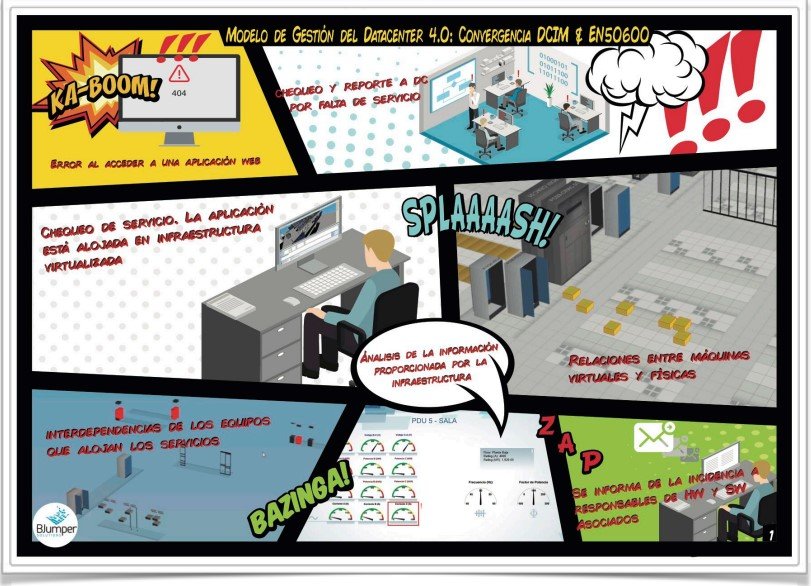
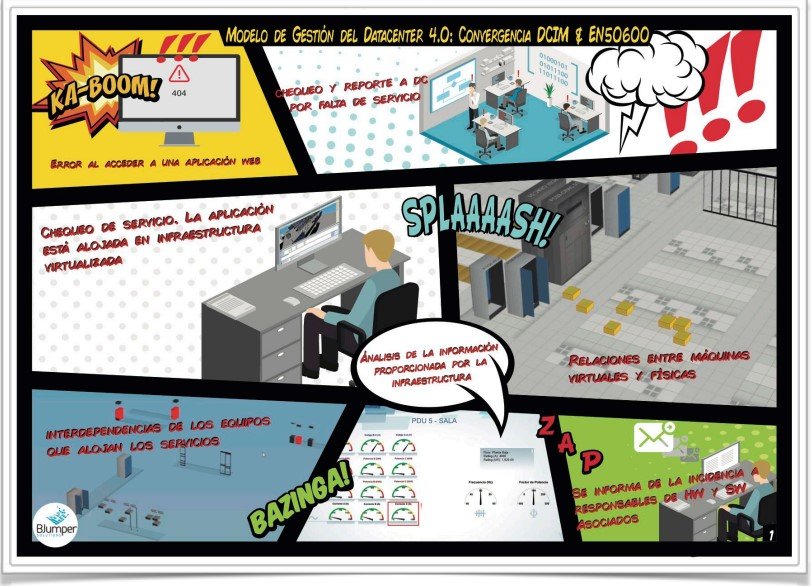
El camino de la integración entre las operaciones y la gestión de servicios IT”). Como ejemplo del procedimiento habitual en la gestión de un Data center mediante la herramienta DCiM, Octavio Vicente mostró un vídeo que podría ser un caso real en la operativa diaria de un Data center estándar.
Cuando hay una caída de servicio, los usuarios que lo detectan informan al técnico responsable del Data center, el cual, gracias a la herramienta DCiM y la configuración de alarmas en tiempo real, permite a éste encontrar el punto de fallo. La herramienta permite localizar el equipamiento físico asociado al servicio que ha fallado, permitiendo delimitar las causas (que podrían venir motivadas por un fallo eléctrico, de refrigeración, de seguridad, de red, de sistemas, etc).
En este proceso, la herramienta permite trazar desde la infraestructura al servicio. Es decir, los servicios, alojados en máquinas virtuales contenidas en máquinas físicas o host, están relacionados. Esta relación lógica se establece en las entidades del modelo, y permiten vincular clúster (compuesto por N hipervisores y N máquinas físicas), con los hipervisores (compuesto por 1 máquina física y N máquinas virtuales), las máquinas físicas (compuestas por N aplicaciones y N máquinas virtuales), las máquinas virtuales (compuestas por N aplicaciones) y las aplicaciones. La siguiente imagen muestra un ejemplo de clúster y cómo aparecerían las interdependencias entre las distintas entidades:
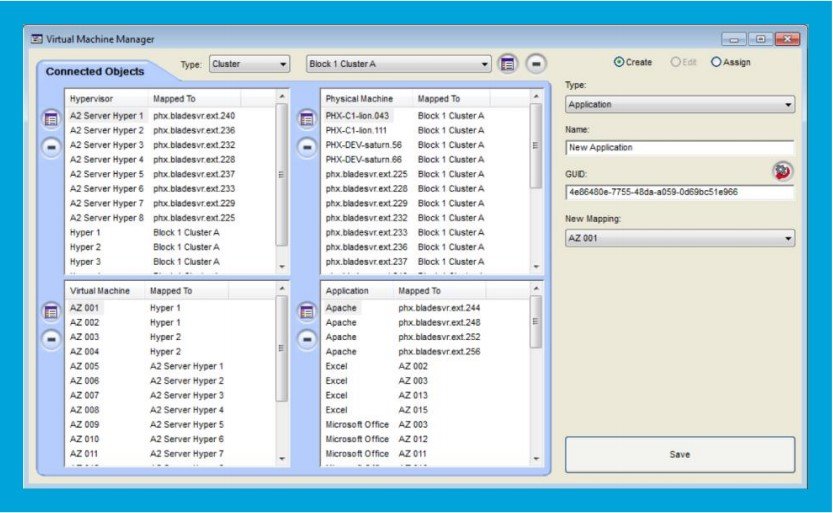
Gracias a la interrelación anterior, en caso de fallo de servicio, es posible identificar los servidores asociados al mismo, incluso en configuraciones complejas, así como la infraestructura de red y eléctrica asociada.
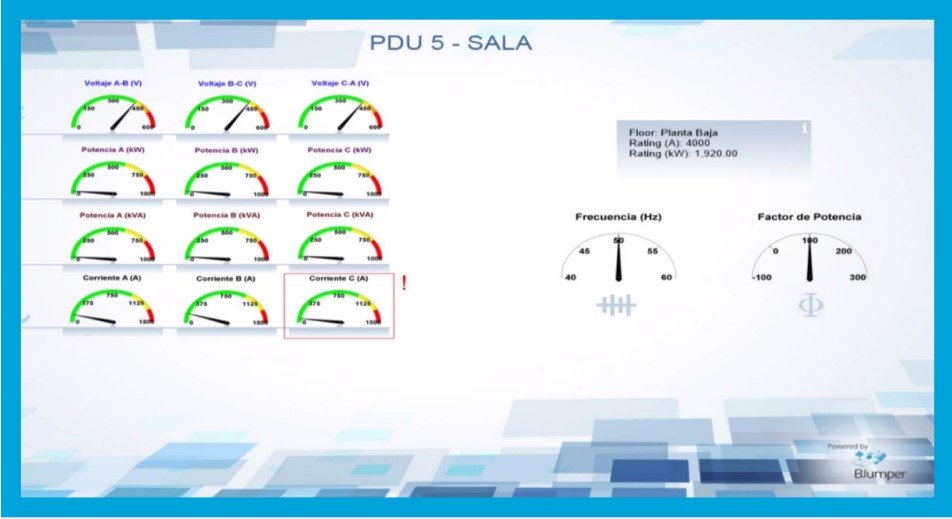
Siguiendo con el ejemplo, el técnico del data center, dado que conoce el servicio que se ha caído y puede vincularlo con las máquinas físicas gracias al DCiM, podría revisar los cuadros de mando de los diferentes elementos que proveen alimentación eléctrica o de red, o bien localizar el punto de fallo a través de las alarmas. Para el ejemplo, el técnico localizaría los cuadros eléctricos que alimentan a las máquinas físicas que proveen alimentación eléctrica, y encontraría el cuadro de mando con el fallo, como se muestra en la siguiente captura (en ella se aprecia una caída de corriente en la fase C):

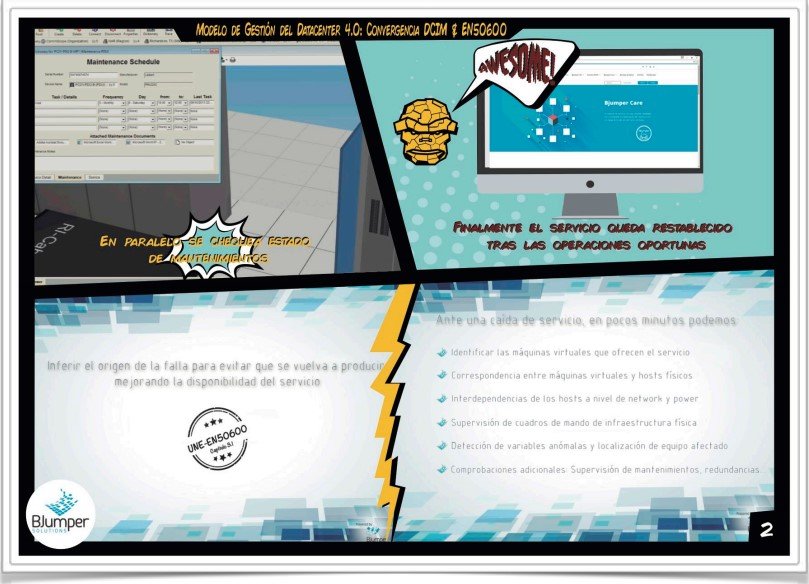
Es posible en este punto consultar la planificación de mantenimiento del equipo que presenta la falla (consultar su manual técnico, sus planes de mantenimiento, garantías, etc.).
De esta forma, se puede inferir el origen de la falla para evitar que se reproduzca, mejorando la disponibilidad del servicio. Continuando con el ejemplo, una vez localizado que la falla se ha producido en el cuadro “PDU-5”, el técnico podría localizar todas las máquinas físicas que se puedan ver afectadas por el mismo y comunicar la incidencia a los responsables asociados a cada una.
Además de los servicios contenidos en las máquinas físicas, que se han visto afectados de forma directa por la caída del cuadro, sería posible también encontrar todas las máquinas que se ven afectadas de manera indirecta, y por tanto sus servicios.
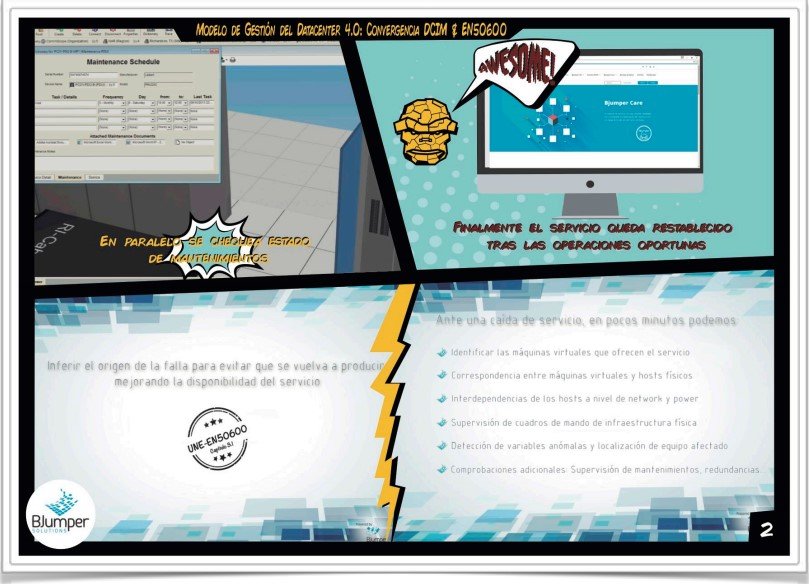
A modo de resumen, Vicente finalizó la ponencia con los puntos clave desarrollados anteriormente, desarrollando la respuesta que ofrece iTRACS DCiM ante una caída de servicio, y que puede llevarse a cabo en pocos minutos:
A. Identificar las máquinas virtuales que ofrecen el servicio.
B. Correspondencia entre máquinas virtuales y hosts físicos.
C. Interdependencias de los hosts a nivel network y power.
D. Supervisión de cuadros de mando de infraestructura física.
E. Detección de variables anómalas y localización de equipo afectado.
F. Comprobaciones adicionales: supervisión de mantenimientos, redundancias, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}