
Una definición comúnmente aceptada de continuidad de negocio, sin perjuicio de la definición estándar contenida en ISO 22301:2012, es la siguiente:
“Continuidad de negocio es la capacidad estratégica y táctica de una organización de planificar para, y responder a, incidentes e interrupciones del funcionamiento normal del negocio, de modo que dicha organización pueda seguir operando y entregando los bienes y/o servicios que dicha organización suministra a un nivel de desempeño predefinido”.
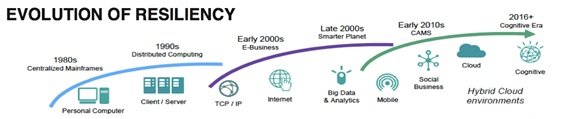
Muy relacionado con el concepto de continuidad de negocio está el de resiliencia, también cubierto en otro estándar ISO de reciente publicación (ISO 22316:2017 Security and Resilience -- Organizational Resilience -- Principles and Attributes). De nuevo, utilizaremos aquí una definición “de trabajo” para ilustrar el concepto en su aplicación a la empresa:
“Resiliencia es la capacidad de estar siempre preparado para lo impredecible. Es la habilidad de una organización de absorber el impacto de una interrupción del negocio a la vez que continúa proporcionando el nivel de servicio requerido”.
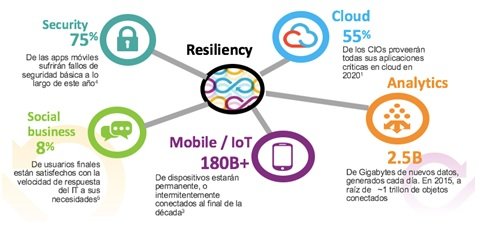
El modelo de negocio de cualquier empresa depende cada vez más de los sistemas de información, y la complejidad y criticidad de los mismos nos plantean retos constantes. En un mundo digital, con necesidades de disponibilidad continuamente crecientes, el nivel de resiliencia de las infraestructuras es cada vez más crítico.
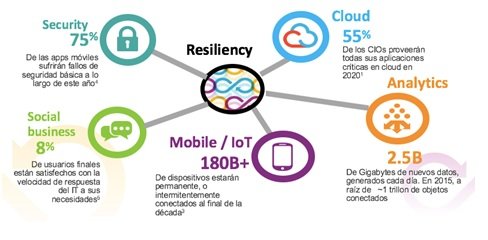
La expectativa de operación “siempre en funcionamiento” (Always ON) del negocio se traslada a requerimientos específicos sobre la infraestructura TI en general, que incluye los centros de proceso de datos. Al mismo tiempo, el movimiento hacia entornos cloud o híbridos ocasiona que la gestión de la resiliencia sea mucho más compleja que el aseguramiento del 100% de disponibilidad de un data center individual. Asociados a los entornos híbridos y a las estrategias “activo-activo”, aparecen ahora en la lista de componentes fundamentales de la estrategia los sistemas de networking, las redes de telecomunicaciones, los centros adicionales de respaldo, el sistema de orquestación software de todo ello y los procesos, políticas y planes de la organización para organizar los medios humanos y materiales y activar los mismos en caso de degradación del servicio o de desastre.
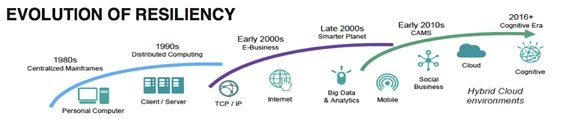
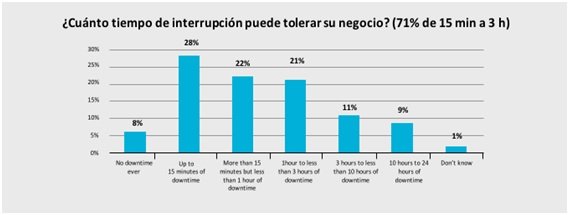
El incremento creciente del coste de las pérdidas por minuto de caída del negocio, sumado al riesgo reputacional en el mercado por ausencia de servicio durante períodos prolongados, obligan a las empresas a poner en práctica rigurosos programas de resiliencia. En ellos, la necesidad de garantizar el funcionamiento Always ON es un aspecto determinante.

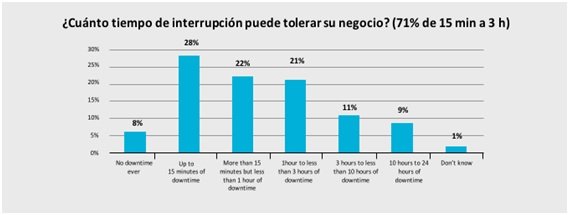
Esto ha sido corroborado por los CIOs de todos los sectores en los 3 últimos años, poniendo de manifiesto la escasa tolerancia a la interrupción del servicio.
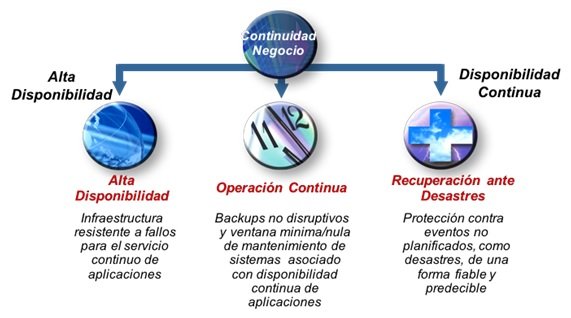
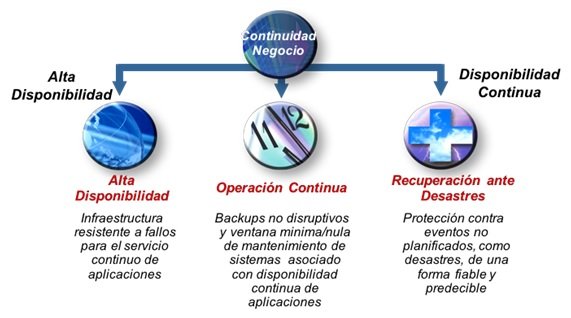
Una vez entendidas la necesidad, importancia y demanda de estrategias, planes e infraestructura de continuidad de negocio, es pertinente recordar los conceptos básicos del ámbito de la continuidad de negocio. Los procesos, aplicaciones, estructuras de datos e infraestructuras técnicas deben diseñarse de manera que se logren los objetivos de:
1. Disponibilidad
2. Operación continua
3. Recuperación ante desastres
La decisión sobre el tipo y sofisticación de programa de resiliencia a implementar en cada caso partirá del análisis del negocio y del análisis de riesgos e impacto en los procesos de negocio. Como parte de este análisis se evalúan los servicios críticos y se definen para cada uno de ellos sus parámetros de disponibilidad (diseño de sistemas en alta disponibilidad) y sus parámetros de recuperación en caso de desastre (RTO, Recovery Time Objective, y RPO, Recovery Point Objective).
Indicador de tiempo de Recuperación (RTO): Tiempo trascurrido desde la toma de decisión de activar el centro de recuperación hasta que efectivamente se está prestando servicios desde el mismo.
Indicador de Pérdida de Datos Máxima Admisible (RPO): Tiempo transcurrido desde que se realizó la última copia de datos utilizada en el centro de recuperación.

Por lo que respecta a los modelos de referencia de alta disponibilidad para protección contra desastres, se presenta a continuación una somera selección de las definiciones y de los marcos de arquitectura a alto nivel:
Alta disponibilidad (HA, High Availability):
- Capacidad para seguir proporcionando el servicio aunque existan paradas no planificadas: averías, caídas de sistemas, corrupción de datos, fallos de energía
§ Proporciona adicionalmente la capacidad de recuperación ante desastres que afecten a un único edificio o sala.
Operación continua:
- Capacidad para seguir proporcionando servicio durante paradas planificadas: copias de seguridad, mantenimiento, nuevas versiones de aplicaciones.
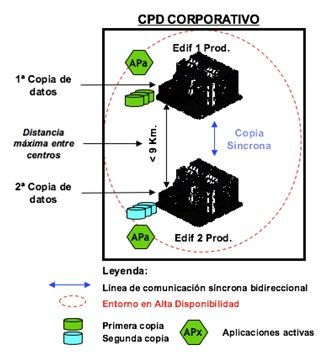
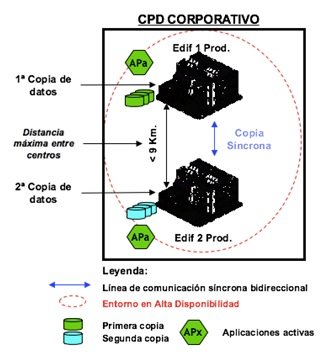
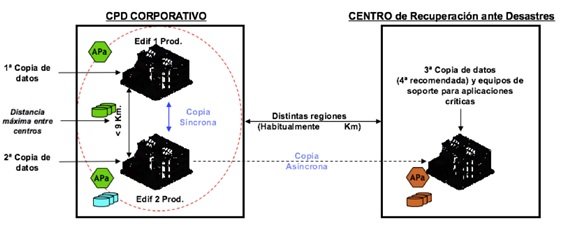
Este modelo de referencia para CPDs atendiendo a desastres establece la conveniencia de utilizar arquitecturas que permitan alta capacidad de recuperación ante desastres de tipo local o regional, mediante la implantación de un tercer centro a mayor distancia (DC activo-activo (HA) + CPD de Recuperación (DR)).
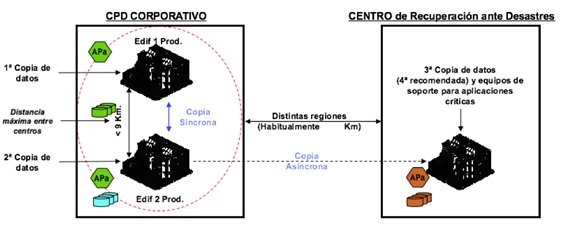
El centro de recuperación no mantiene producción. Si las distancias lo permiten, se puede compartir con los entornos de desarrollo y pruebas.
En el momento de tomar decisiones de diseño deberemos tener una idea clara de:
· El peso que tiene la disponibilidad en la operación (Always ON?)
· El RTO/RPO en caso de desastre
· El grado de protección
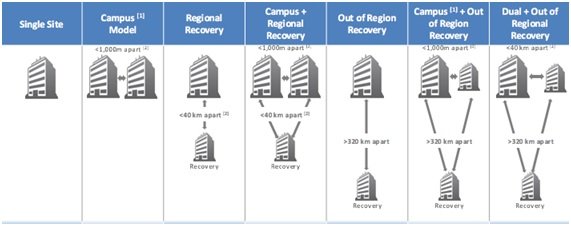
En función de lo anterior, seleccionaremos la mejor topología de entre todas las combinaciones posibles:
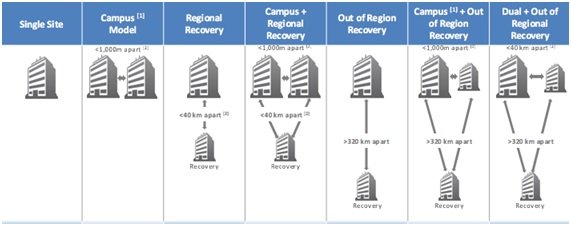
Utilizando estos parámetros los arquitectos de TI deberán diseñar del modelo más adecuado para los sistemas de información, que incluye los centros de proceso de datos que albergarán dichos sistemas.
Llegados a este punto, las cuestiones a las que nos enfrentamos son, entre otras, las siguientes: ¿Siguen vigentes los modelos tradicionales de CPD? ¿Debe detenerse nuestro análisis en el CPD? ¿Qué ha cambiado con los modelos cloud? ¿Cómo influyen la externalización y la contratación “as a service”? ¿Y las nuevas filosofías de centros edge?
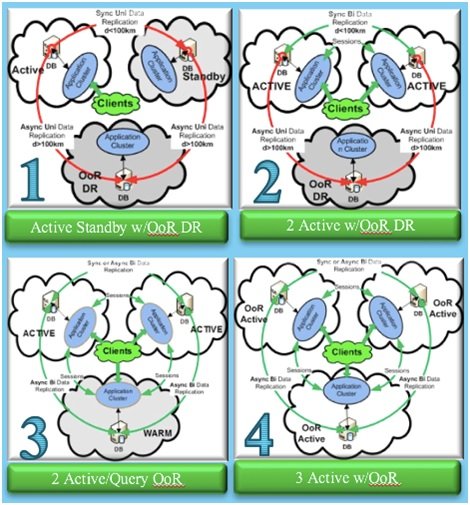
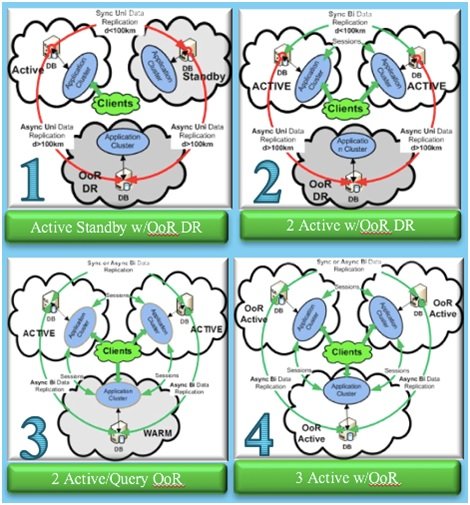
IBM, en 2014, definió el espectro conceptual de los distintos modelos de CPD correspondientes a una evolución de las infraestructuras hacia Always On. Se trata de un camino a recorrer sobre el modelo de 3 centros anteriormente citado, en la que se comienza con un único centro activo (estado1) y se puede llegar a una tríada de centros activos (estado 4), donde la compartición de recursos se optimiza y podemos ejecutar nuestras aplicaciones deslocalizadamente con suficiente respaldo y un nivel óptimo de recursos.
Como decíamos al comienzo del artículo, este modelo adquiere hoy en día más complejidad, ya que los centros no sólo pueden ser centros corporativos propios, sino centros de servicios de terceros (colocation/hosting) o centros de servicio cloud públicos, o combinaciones de ellos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Los conceptos de disponibilidad, operación continua y recuperación ante desastres se amplían ahora por tanto a CPDs externos y a las interconexiones entre ellos y con los centros de la empresa. Los requerimientos de disponibilidad siguen totalmente vigentes y aplicables a CPDs externos, ya sean colocation, hosting o cloud:
· Necesidad de contar con diseños contrastados (o certificados) con un nivel de fiabilidad determinado, dotándoles de la adecuada redundancia y flexibilidad para potenciar el diseño HA de los sistemas TI que aloja.
· De especial importancia: diseño de las comunicaciones entre centros y disponer de múltiples operadores.
· Estos requerimientos deben traducirse en acuerdos de nivel de servicio (SLA) contractuales de disponibilidad del CPD y de las infraestructura de TI/comunicaciones
Asimismo, en el caso de la operación continua, no se admitirá un centro que no permita un mantenimiento concurrente, es decir, la capacidad de realizar el mantenimiento y, en un caso extremo, la sustitución, de cualquier componente del centro de proceso de datos, sin provocar afectación a los servicios de TI allí alojados.
Los requerimientos de recuperación ante desastres deben garantizar que un negocio que ha sufrido una interrupción y que debe recuperarse desde un centro alternativo contará la adecuada capacidad de recursos en el tiempo máximo permitido. Esto se consigue con equipos humanos experimentados, planes de contingencia comprobados y CPDs de respaldo que puedan proporcionar un nivel de disponibilidad muy cercano al de los centros de producción.
En este último punto se cierra el círculo entre el data center individual y el esquema global de continuidad de negocio, puesto que en este último se aplican (¡deben aplicarse!) prácticas ya de sobra conocidas en la operación de centros de datos, como son los procedimientos en caso de emergencia (EOPs, por sus siglas en inglés) y los simulacros (Scenario Testing). De igual manera que los EOPs de un CPD individual tienen un valor limitado y dudoso hasta el momento en que han sido efectivamente probados mediante un simulacro, los planes de continuidad de negocio deben “activarse” y simularse de modo periódico para encontrar deficiencias, fallos de diseño, problemas que no pueden preverse al hacer la planificación “en papel”, pero que aparecen en la realidad, etc.
Los gestores de centros de proceso de datos deben ser conocedores de su papel, y el papel del CPD en la estrategia global de continuidad de negocio de la empresa y propiciar las oportunidades para obtener una mayor visibilidad de las interdependencias entre estos y aquella. De igual manera deberán actuar los responsables de las estrategias y planes de continuidad de negocio. Así, conjuntamente y de un modo integrado, estos grupos lograrán fortalecer de un modo tangible la exposición de la empresa a los potenciales riesgos y, en general, darán un paso más hacia la consecución de “la capacidad de estar siempre preparado para lo impredecible”.
Artículo escrito por Alfonso Aranda, tutor de DCPro y Data Center Specialist
Operations y Head of Global Data Center Operations en IBM.
Aprenda más con la capacitación de DCPro
DCProfessional
Development, como líder de mercado en soluciones de formación para la industria
data center, ofrece la oportunidad de entender la industria del centro de datos,
consiguiendo una cualificación internacional, proporciona a los profesionales
un conocimiento imprescindible con el fin de conseguir la eficiencia operativa
y la optimización de los recursos
para la reducción de costes, y la disminución de las caídas no programadas de
los sistemas. Más de 8.000 profesionales se han formado con nosotros a nivel
mundial. Nuestros trainings permiten a los profesionales sacar provecho y
aprender de las tecnologías que influyen en las operaciones de data centers en
todo el mundo, de la mano de los expertos más prestigiosos y con más
experiencia de la industria con una gran visión de futuro.