
Por Steven Carlini, vicepresidente de la división de TI de centros de datos e innovación de Schneider Electric
Décadas antes de que la IA se convirtiera en la palabra de moda, estuve involucrado en un proyecto para respaldar el centro de datos principal del minorista más grande del mundo.
El CIO me mostró con orgullo una computadora nueva y de última generación que podía aprobar y procesar pagos con tarjeta de crédito en menos de un segundo, lo que ayudaba a prevenir el fraude y al mismo tiempo mejoraba la experiencia del cliente.
La velocidad y eficiencia de esta computadora cambiaron las reglas del juego: ¡la tecnología informática al rescate! No hace falta decir que esta tecnología de TI con forma de caja grande era ahora una parte fundamental del ecosistema de ese minorista y necesitaba energía y refrigeración adecuadas para mantener su disponibilidad.
De hecho, los tiempos han cambiado, ya que la infraestructura física necesaria para soportar esta computadora era un simple aire acondicionado en la sala de computadoras y un UPS en la sala eléctrica. Puede que la IA esté a la vanguardia de nuestra industria hoy en día, ¡pero hace décadas era esta máquina la que estaba a la vanguardia!
Ahora los servidores de IA presentan desafíos enormes para la energía y la refrigeración debido a su altísima producción de calor y su densificación.
La tecnología evoluciona
A finales de la década de 1980, la industria había dejado atrás las alguna vez populares minicomputadoras como la del gran minorista. El mundo de la informática pasó a los ordenadores Client Server modelo Intel x86, IBM PowerPC o Sun SPARC, controlados por sistemas operativos Windows o variantes de UNIX. La industria de las minicomputadoras desapareció debido a adquisiciones y quiebras.
A mediados de la década de 1990 se produjo el auge de la computación en la nube, con servidores basados principalmente en X86 que formaban granjas de servidores que constituían la columna vertebral de la nube. Los procesadores han ido evolucionando desde que Intel introdujo el primer microprocesador comercial en 1971.
El cofundador de Intel, Gordon Moore, ideó la Ley de Moore en 1975 que decía: la potencia informática se duplica aproximadamente cada dos años, mientras que los microchips mejores y más rápidos se vuelven menos costosos.
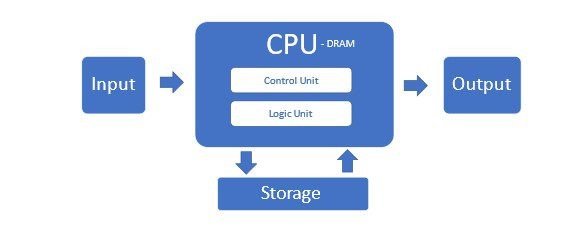
La Ley de Moore tuvo un funcionamiento increíble hasta hace poco, cuando los límites físicos comenzaron a limitar la cantidad de microtransistores que se podían incluir en una CPU asequible. Estos servidores tradicionales que utilizan CPU x86 comprenden la mayoría de los centros de datos en lo que se llama arquitectura Von Neumann.
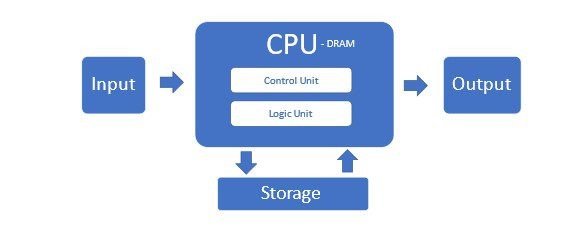
Pero esta arquitectura no es adecuada para servidores de IA y sus clústeres. Sufre porque las CPU no pueden procesar eficientemente el gran flujo de datos y la memoria tiene un cuello de botella en esta configuración.
Nuevos requisitos para servidores de IA
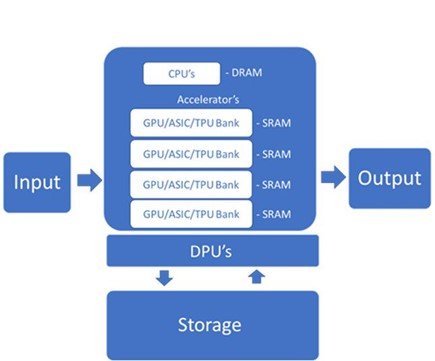
Los servidores de IA requieren aceleradores de propósito especial, como Unidades de procesamiento de gráficos (GPU) o circuitos integrados de aplicaciones específicas (ASIC), como las Unidades de procesamiento de tensores (TPU) de Google o el Ascend 910 de Huawei. Estos aceleradores pueden manejar las altas velocidades de datos necesarias para el entrenamiento de modelos de IA e inferencia.
Estos chips tienen una memoria saludable en el chip para aumentar la velocidad y la eficiencia del procesamiento. Dentro del servidor, son administrados por CPU y los datos se pasan mediante interconexiones de gran ancho de banda. Las memorias multipuerto permiten paralelizar lecturas y escrituras para una mayor velocidad.
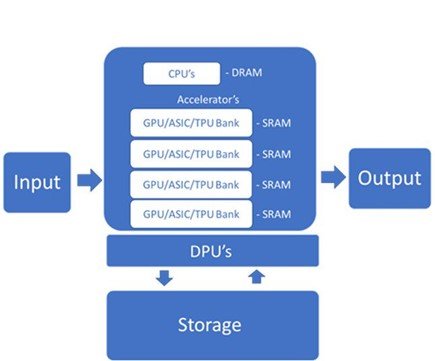
Las DPU funcionan con CPU y GPU para mejorar la potencia informática y el manejo de cargas de trabajo de datos modernas cada vez más complejas. La Unidad de procesamiento de datos (DPU) es un componente relativamente nuevo del servidor de IA que descarga de la CPU tareas de red, almacenamiento y administración de procesamiento intensivo.
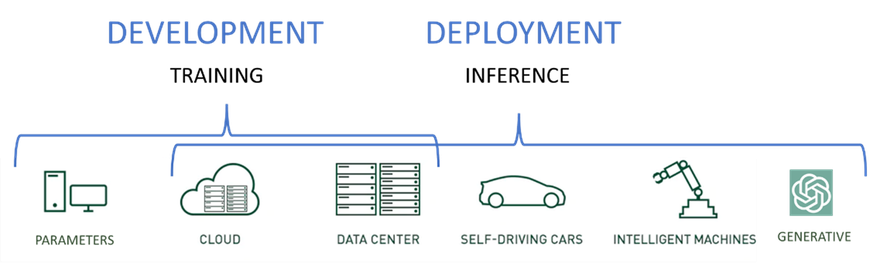
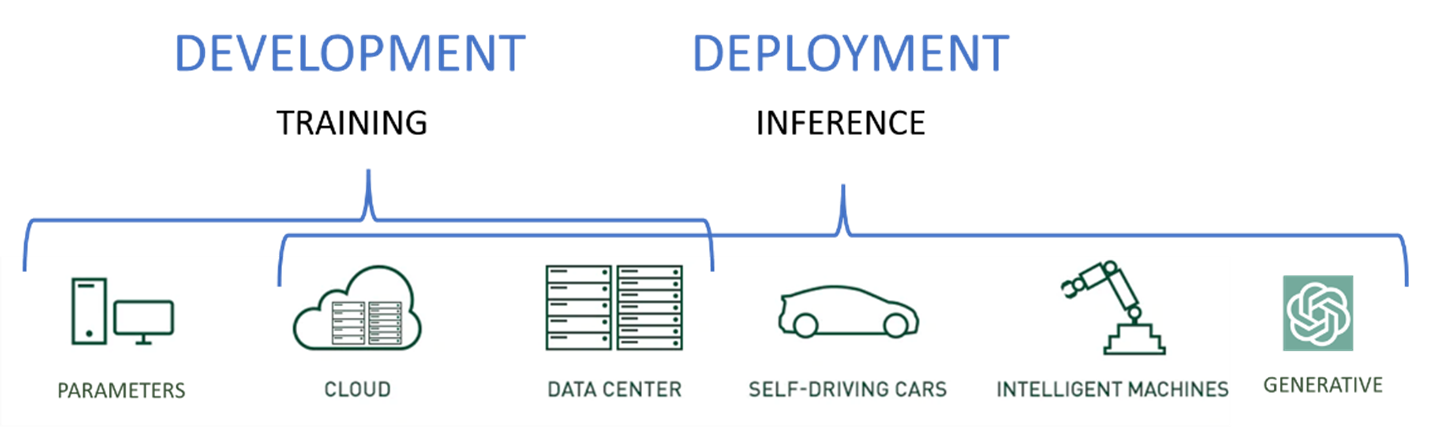
Cargas de trabajo de entrenamiento e inferencia
Los servidores de IA de última generación ejecutan dos tipos distintos de cargas de trabajo: capacitación e inferencia.
- Cargas de trabajo de capacitación: se utilizan para desarrollar modelos iniciales y mejorar modelos basados en nuevos datos e información aprendida.
- Cargas de trabajo de inferencia: uso de los modelos desarrollados durante el entrenamiento y predicción del resultado en función de nuevos datos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Si bien los modelos de inferencia pueden ejecutarse en servidores de entrenamiento súper potentes, es mejor ubicarlos más cerca de los usuarios y de la entrada de datos para aumentar la velocidad, reducir el desorden de la red y reducir la latencia.
La mayoría de las veces, los servidores de inferencia también ejecutarán una versión reducida del modelo entrenado. Las GPU aceleradoras siguen siendo fundamentales para lograr los objetivos de nivel de servicio empresarial, los SLA y los requisitos para las cargas de trabajo de inferencia en la mayoría de los casos.
Nuevo documento técnico 110 sobre servidores de IA
La tecnología de hardware necesaria para admitir todas las versiones de IA, aprendizaje automático (ML), IA generativa (GAI) y modelos grandes de lenguaje (LLM), por nombrar solo algunas, es verdaderamente un ecosistema que incluye potentes dispositivos de punto final.
Los teléfonos inteligentes pueden ingresar texto, imágenes e incluso videos a través de redes potentes y de alta capacidad a los servidores de inferencia que ejecutan una versión reducida de los modelos entrenados que aceptan entradas en el modelo y devuelven el resultado que podría ser una decisión, un texto, descripción, una imagen o incluso música.
Para obtener una visión detallada de la infraestructura física necesaria para respaldar esta nueva generación de servidores de IA y las mejores prácticas para su implementación, el Centro de Investigación de Gestión de Energía de Schneider Electric acaba de publicar nuestro nuevo Libro Blanco 110: La disrupción de la IA: Desafíos y orientación para el diseño de centros de datos aquí . .