{kind=link}
Whenever there is a utility outage, a data center runs on reserve energy sources. In theory, this situation provides uninterrupted services until the utility is restored to normal. The interesting questions to ask on this are:
· What happens when a critical plant items also fails whilst running on reserve energy sources?
· What happens when the all reserve energy sources are depleted?
In the first case the amount of reserve energy is reduced such that the absolute time to data center failure is shortened. In the second case the data center fails completely.
Data centers normally house many business processes residing on technology platforms. Invariably the processes have different
levels of importance to the organization as a whole. When a data center fails due to a lack of reserves (power, water or gas) during a utility outage, the whole data center fails at the same time; in this instance, taking down all business processes at the same time regardless of their respective importance to the organization
This scenario, of a dysfunctional failure of systems in the face of adequate time to react along with factors that can be quantified and understood, is irrational. What is needed is a way of preserving the uptime of business critical processes as long as possible by load-shedding processes of lower criticalities to maintain the operation of those with the highest priority.
The implementation of a control system to manage such a failure scenario requires knowledge of:
- Time to failure based upon reserves – e.g. how much fuel, battery, kinetic energy, water?
- MEP plant operational status – e.g. has any of the plant failed e.g. generators at N-1
- IT operational status – where each process resides physically and logically
- Process criticality levels – e.g. critical, important, desirable etc.
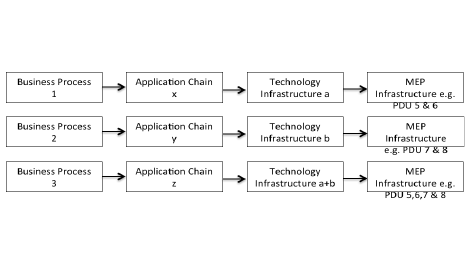
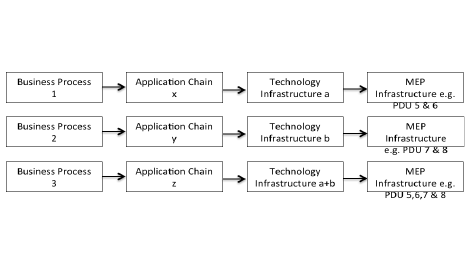
The linkage between organizational processes, IT services and MEP can be highly complex. Typically one process involves a group of applications forming an application chain, which is deployed across numerous hardware platforms. These relationships must be understood in order to ensure the correct IT services are load-shed.

Figure 1: Simplified illustration of the interdependencies between business processes, application chains and the physical environment
The problem arises in most instances that there is no systems management tool that has complete overview of all IT services in the data center; instead these tools are siloed e.g. network, server, security, storage etc. Ideally the automated decision process should be carried out by a control system that is linked to, and has control over, all system management tools. However this brings about potentially increased risk particularly in terms of security and segregation of systems.
A further consideration is the load-shedding control system that initiates the shutting down of business processes. The control system makes recommendations regarding what lower priority processes to shutdown and calculates the residual additional uptime available to the high priority processes.
Given sufficient time, the decision to shut business processes down will not take place without senior management authorization. In some instances, however, there will not be enough time for human authorization e.g. in the case of a failed generator resulting in N - 1 capacity. In such cases, the decision must be automated to avoid a complete data center outage and to mitigate recovery failures caused by a dysfunctional shutdown.

Figure 2: Example Of Time Remaining To Data Centre Shutdown Based On Fuel Oil Status

Figure 3: IT Load Shedding Functional Overview
This is Part 1 of a 2 part series.
Ed Ansett will be presenting on this topic at the forthcoming DatacenterDynamics Converged Conference in New York on March 12th