
Por Steven Carlini, Vice-Presidente de TI e Inovação de Data Center, Schneider Electric
Décadas antes de a IA se tornar a palavra da moda, eu estava envolvido em um projeto para auxiliar o principal Data Center do maior varejista do mundo.
O CIO orgulhosamente me mostrou um computador novo e de última geração que pode aprovar e processar pagamentos com cartão de crédito em menos de um segundo, ajudando a prevenir fraudes e melhorando a experiência do cliente.
A velocidade e eficiência deste computador foi um divisor de águas: a tecnologia computacional ao resgate! Não é preciso dizer que esta tecnologia de TI em forma de caixa grande era agora uma parte crítica do ecossistema do varejista e precisava de energia e refrigeração adequados para manter a sua disponibilidade.
De fato, os tempos mudaram, pois a infraestrutura física necessária para suportar esse computador era um simples ar-condicionado na sala de informática e um nobreak na sala elétrica. A IA pode estar na vanguarda da nossa indústria hoje, mas décadas atrás era essa máquina que estava na vanguarda!
Os servidores de IA agora apresentam enormes desafios para energia e resfriamento devido à sua alta produção de calor e densificação.
A tecnologia evolui
No final da década de 1980, a indústria havia deixado para trás os outrora populares minicomputadores, como o grande varejista. O mundo da computação mudou para computadores Intel x86, IBM PowerPC e Sun SPARC Client Server, controlados por sistemas operacionais Windows e variantes UNIX. A indústria de minicomputadores desapareceu devido a aquisições e falências.
A metade da década de 1990 viu o surgimento da computação em nuvem, com servidores baseados principalmente em X86 formando fazendas de servidores que formavam a espinha dorsal da nuvem. Os processadores vêm evoluindo desde que a Intel introduziu o primeiro microprocessador comercial em 1971.
O cofundador da Intel, Gordon Moore, criou a Lei de Moore em 1975, que dizia: o poder de computação dobra aproximadamente a cada dois anos, enquanto microchips melhores e mais rápidos se tornam mais baratos.
A Lei de Moore teve um funcionamento incrível até recentemente, quando os limites físicos começaram a limitar o número de microtransístores que poderiam ser colocados em uma CPU acessível. Esses servidores tradicionais que usam CPUs x86 compreendem a maioria dos Data Centers no que é chamado de arquitetura Von Neumann.
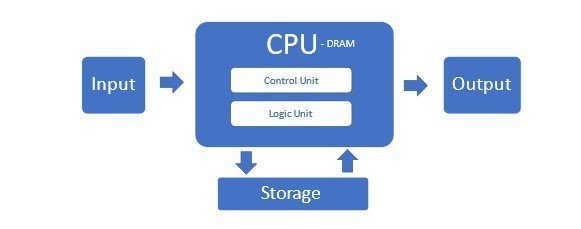
Mas essa arquitetura não é adequada para servidores de IA e seus clusters. Ela sofre porque as CPUs não conseguem processar com eficiência o grande fluxo de dados e a memória tem um gargalo nessa configuração.
Novos requisitos para servidores de IA
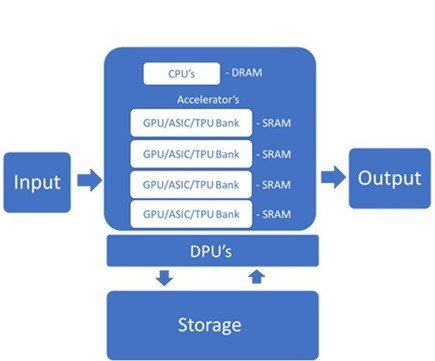
Os servidores de IA exigem aceleradores de propósito especial, como Unidades de Processamento Gráfico (GPUs) e circuitos integrados específicos de aplicativos (ASICs), como as Tensor Processing Units (TPUs) do Google e o Ascend 910 da Huawei. Esses aceleradores podem lidar com as altas taxas de dados necessárias para o treinamento e a inferência de modelos de IA.
Esses chips têm uma memória on-chip saudável para aumentar a velocidade e a eficiência do processamento. Dentro do servidor, eles são gerenciados por CPUs e os dados são passados por interconexões de alta largura de banda. A memória multiportas permite paralelizar leituras e gravações para maior velocidade.
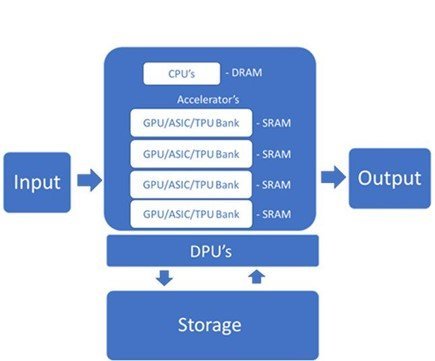
As DPUs trabalham com CPUs e GPUs para melhorar o poder de computação e lidar com cargas de trabalho de dados modernas e cada vez mais complexas. A Unidade de Processamento de Dados (DPU) é um componente relativamente novo do servidor de IA que descarrega tarefas de rede, armazenamento e gerenciamento de computação intensiva da CPU.
Cargas de trabalho de treinamento e inferência
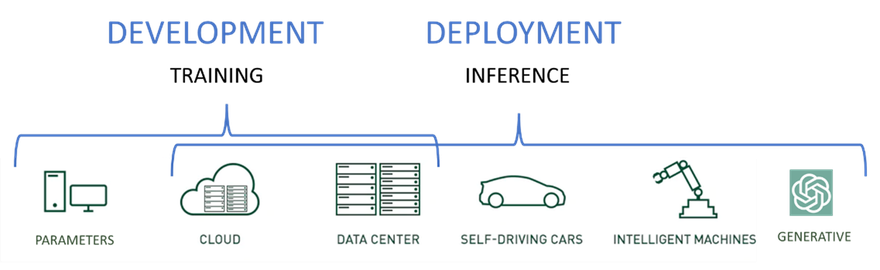
Os servidores de IA de próxima geração executam dois tipos distintos de cargas de trabalho: treinamento e inferência.
- Cargas de trabalho de treinamento: são usadas para desenvolver modelos iniciais e melhorar modelos com base em novos dados e informações aprendidas.
- Cargas de inferência: Utilizar os modelos desenvolvidos durante o treinamento e prever o resultado com base em novos dados.
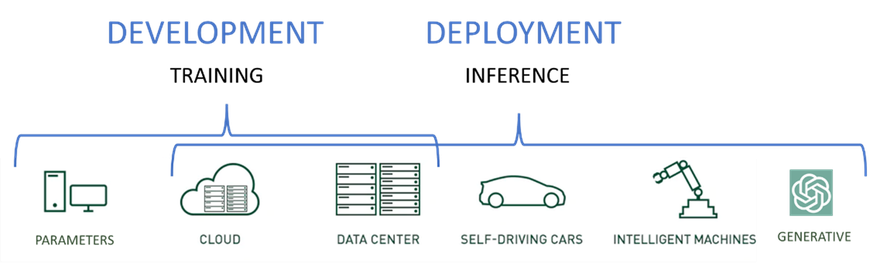
Embora os modelos de inferência possam ser executados em servidores de treinamento superpoderosos, é melhor colocá-los mais perto dos usuários e da entrada de dados para aumentar a velocidade, reduzir a desordem da rede e reduzir a latência.
Na maioria das vezes, os servidores de inferência também executarão uma versão reduzida do modelo treinado. Os aceleradores de GPU continuam sendo essenciais para atingir metas de nível de serviço corporativo, SLAs e requisitos para cargas de trabalho de inferência na maioria dos casos.
Novo documento técnico 110 sobre servidores de IA
A tecnologia de hardware necessária para suportar todas as versões de IA, machine learning (ML), IA generativa (GAI) e modelos de linguagem grande (LLMs), para citar apenas alguns, é realmente um ecossistema que inclui dispositivos de endpoint poderosos.
Os smartphones podem inserir texto, imagens e até vídeos em redes poderosas e de alta capacidade para servidores de inferência que executam uma versão reduzida dos modelos treinados que aceitam entradas no modelo e retornam o resultado que pode ser uma decisão, texto, descrição, imagem ou até mesmo música.
Para obter uma visão detalhada da infraestrutura física necessária para suportar esta nova geração de servidores de IA e as melhores práticas para a sua implementação, o Centro de Pesquisa de Gestão de Energia da Schneider Electric acaba de publicar o nosso novo White Paper 110: “A disrupção da IA: Desafios e Orientação ao design de Data Centers Design” aqui.



{kind=link}
{kind=link}
{kind=link}
{kind=link}