
We are all familiar with claims that ‘our systems can give you five 9s, guaranteed’ where five 9s means 99.999 percent availability of something or other. But what does that mean to the end user, the final arbiter? It depends on his viewpoint.
The disk or CPU supplier may well guarantee 99.999 percent availability of his disk/CPU but does that mean the application will be 99.999 percent available? No. 99.999 percent availability of a service is a myth unless a large amount of thought and work goes into a system.

Whose viewpoint?
The viewpoints of interest are those of the end user of the IT service and of the IT person’s view of the system. A computer system can be working perfectly yet to the end user be perceived as not available because the service he uses is not available.
How can this be? The simple reason is that there are several types of ‘outages’ which can impact a system or a service. One is a failure of hardware or software so that an application or service is unavailable: this is a physical outage.
The other outage is a logical outage where the physical system is working but the user cannot access the service properly, that is, in the way agreed with IT at the outset.
What on earth is a logical outage? There are several types, not including a degraded (slow) service, which users will often class as an unavailable service.
- Processing is severely hindered by a constraint on the system set by operations parameters, for example, maxusers=100.
- Another type can be found where processing is done on a class of transaction basis as it was in the IBM Information Management Systems (IMS). In this system, transactions were assigned a class (A, B, C etc) and computer regions were assigned classes which they were allowed to process. If only one region was configured to process C transactions, there would be a rapid build-up of a queue of class C transactions and eventually the response times would be so bad that the service on class C transactions would be deemed ‘down’ by users.
- Security attacks. These are legion and increasing in characteristics, number and severity. They can cause a system to be taken down by the IT department as a damage limitation exercise or the data locked/encrypted/stolen by the perpetrators. The recovery time here is a variable feast
- Incorrect operations such as running jobs in the wrong order. Witness the London Stock Exchange outage on March 1st 2000. The cause of this was given as the fact that jobs had run in the wrong order so that Job 2 on system 2 ran before Job 1 on system 1, instead of the reverse. The resulting databases were in a mess. My suspicion is that one system recognised it was a leap year and acknowledged 29th February and the other didn’t.
- Human error in various guises can cause services to be unavailable to the specification expected by the end use. One is outlined above. Human error is unavoidable, especially in a volatile IT environment, but can be minimized by rigorous change management and automated operations. 6. The unusable web site (and there are plenty about) is often classed as ‘down’ by clients who, according to surveys, have a patience of less than 7 seconds before going elsewhere. Other surveys point to patience limits of 100s of milliseconds. To the casual user or potential buyer, an unusable web site is an unavailable web site.
In summary then, the emphasis on what is up (available) and down (not available) should focus on the service of which the system is a part and not the individual components. There are service outages to which there is no physical cause and these should be considered carefully in the design, implementation and operation of High Availability services and systems.
There is also a time element called ‘ramp up’ time which s that taken to restore the service to its SLA (Service Level Agreement ) specification. This is an integral part of any reported ‘outage’ time.
Availability: The Truth
“You can fool some of the people all of the time, and all of the people some of the time, but you cannot fool all of the people all of the time”. Abraham Lincoln, (attributed).
This statement is supported by the statement attributed to various sources “There are lies, damned lies and statistics”. Without casting aspersions on the veracity of some outage figures (or availability statistics), I do feel that some examination of them is needed as some look ludicrously minimal.
{kind=link}
{kind=link}
{kind=link}
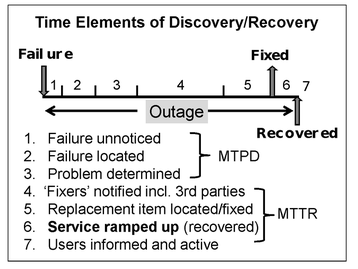
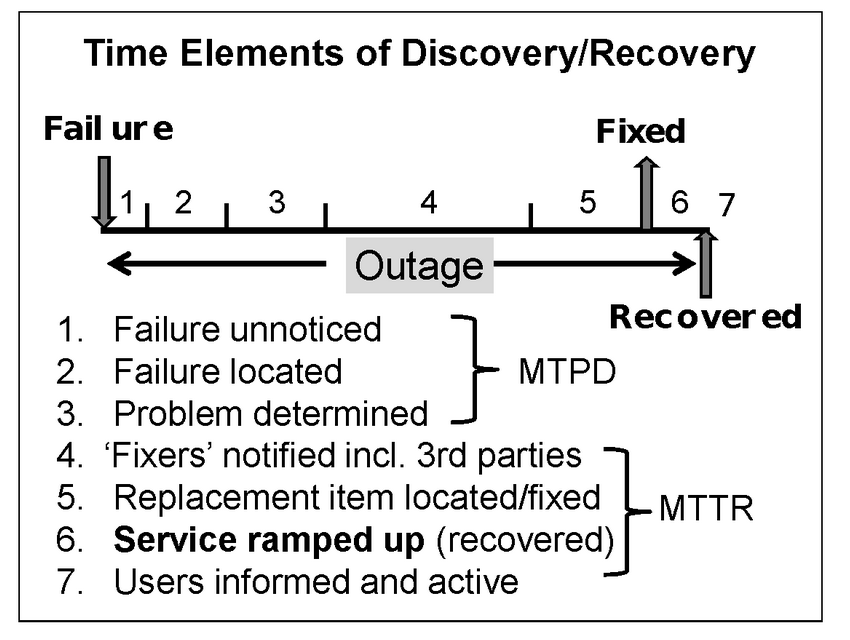
The diagram illustrates the phases of an outage, each of which needs to be addressed to increase availability. This implicitly means reducing non-availability if you think about it carefully.
Each element needs attention but how? There are numerous factors which cause outages (physical and logical) and they are not covered by glitzy hardware and software although they do play a significant role. One killer element in outages is the ramp up time which is the time to restore the whole system to working order as specified in an SLA or expected. Fixing a problem does not necessarily restore the system to full health.
A recent outage in a major public system showed a recovery at a certain time but stated that the service was not available until 2 hours later, while data integrity was restored. Just using the repair time as the outage time in an availability calculation is not quite fair. Ramp up time might be small compared to the fix time but often it is much larger and should be included in availability percentages.
In summary, there are more things that can affect the availability of a service than simply hardware and software failures. There are logical failures as well as physical ones.
High Availability: The Steps
The classification below shows the areas needing attention under twenty-odd headings which will help to focus ones efforts instead of trying to boil the ocean on all aspects which come to mind.
- A. Availability by systems design/modification
- B. Availability by engineering design (choosing resources)
- C. Availability by application design or selection
- D. Availability by configuration of resources
- E. Availability by outside consultancy
- F. Availability by vendor support
- G. Availability by proactive monitoring of activity
- H. Availability by technical support excellence
- I. Availability by operations excellence
- J. Availability by retrospective analysis of events
- K. Availability by application monitoring
- L. Availability by automation of procedures and operations
- M. Availability by reactive recovery
- N. Availability by partnerships with third parties
- O. Availability by change management and related disciplines
- P. Availability by performance/capacity management
- Q. Availability by monitoring and total resource visibility
- R. Availability by cleanliness of data centers
- S. Availability by anticipation (be prepared)
- T. Availability by teamwork (cooperation)
- U. Availability by organization (fit for purpose)
- V. Availability by eternal Vigilance (security)
- W. Availability by location of facilities
These areas are covered in Dr Critchley’s book, ‘High Availability IT Services’ .